- AI Fire
- Posts
- ⚙️ Context Engineering: Build Truly Intelligent AI Systems
⚙️ Context Engineering: Build Truly Intelligent AI Systems
Transform your AI from a simple tool into an intelligent partner. Our guide to context engineering gives you the strategies to build faster, smarter agents.
Neil Phan
July 30, 2025

What's your BIGGEST challenge when building with AI agents? |
Table of Contents
Introduction: The New Era Of AI Interaction
Imagine a scenario: you deploy a state-of-the-art AI customer service agent. Initially, it performs flawlessly. But after a few weeks, customers complain that it starts offering incorrect discount information, inventing non-existent policies, and repeatedly asking for information that customers have already provided. Your business now faces not only customer frustration but also potential financial losses. The problem here isn't your prompt; it's a deeper, more insidious issue: context degradation.
In the world of increasingly autonomous AI agents, traditional prompt engineering - which focuses on crafting the perfect command for a single task - is no longer powerful enough. We are entering a new era that demands a more robust methodology: Context Engineering.

Context Engineering is the art and science of designing, managing, and optimizing the flow of information that an AI agent receives and remembers. It's not just about "providing information," but about building an "informational nervous system" for the AI. Think of it as managing a complex conversation where you must constantly track what has been said, what is crucial to remember, and what can be safely discarded to avoid noise. When done right, this technique transforms clunky AI interactions into smooth, intelligent, and effective dialogues capable of executing complex, long-running tasks.
In this comprehensive guide, we will dive deep into nine practical Context Engineering strategies, from basic to advanced. Whether you are building customer service chatbots, automated research assistants, or complex workflows, these techniques will make your AI agents smarter, faster, and more reliable than ever before.
Why Context Engineering Matters More Than Ever
Before diving into the techniques, we need to understand the nature of the problem. Leading AI researcher Andrej Karpathy has famously compared Large Language Models (LLMs) to a new kind of "operating system," with the context window acting as its RAM - the limited random-access memory of that OS. All information the agent needs to think and act must reside in this "RAM." When an AI agent operates autonomously, continuously interacting and accessing data, this "RAM" quickly becomes filled and polluted.

This leads to a series of critical issues, not just technically, but from a business perspective as well:
Context Poisoning: This is when incorrect information gets "stuck" in the memory.
Business Example: A sales agent reads a 20% discount figure from an unofficial source and saves it to memory. It then repeatedly offers this discount to every customer, causing revenue loss until it is discovered and corrected.
Context Distraction: When there is too much irrelevant information, the LLM must bear an excessive "cognitive load." Like a person trying to listen to five conversations at once, the agent will be unable to focus on the primary task and will provide generic or off-topic answers.

The "Needle in a Haystack" Problem: Recent research has identified a phenomenon called "Lost in the Middle," where LLMs tend to pay more attention to information at the beginning and end of a context window, often ignoring critical details in the middle. This means your most important information could be buried and never used.

Context Drift: In long-running tasks, the original objective can fade.
Project Management Example: An agent is tasked with "drafting a new product launch plan." However, during interactions, the user repeatedly asks it to perform minor side tasks like "check my email" or "summarize this unrelated article." Gradually, the context fills up with these side tasks, and the agent forgets its core mission of completing the launch plan.
Furthermore, the economic impact of context is immense. Every token fed into the context window costs API fees. An inefficient context management system will burn your money processing unnecessary information.
The solution to these challenges isn't to search for a perfect prompt but to build an intelligent context management system. That is the essence of Context Engineering.
Learn How to Make AI Work For You!
Transform your AI skills with the AI Fire Academy Premium Plan - FREE for 14 days! Gain instant access to 500+ AI workflows, advanced tutorials, exclusive case studies and unbeatable discounts. No risks, cancel anytime.
Effective Context Management Strategies
1. Short-Term Memory: The Foundation Of Every Conversation
Short-term memory is the most fundamental layer, allowing an agent to remember recent interactions. Most AI-building platforms offer simple settings where you can configure the agent to remember a certain number of recent interactions. This approach has the advantage of low latency and ease of implementation.

Example: When a user says, "My customer ID is
KH-8675," the agent can correctly answer the question "What is my customer ID?" a moment later because the information is still in its short-term memory.
However, for tighter control, using an external database like PostgreSQL offers significant advantages in persistence, queryability, and shared memory across multiple agents. This approach allows you to design a clear message table structure, for instance, a table with columns like: session_id, message_order, role (user/assistant), content, and timestamp. This not only makes debugging easier but also opens up possibilities for deep analysis of conversation patterns to improve the agent over time. The trade-off here is slightly higher latency compared to in-memory storage.
2. Long-Term Memory: Building Durable Intelligence
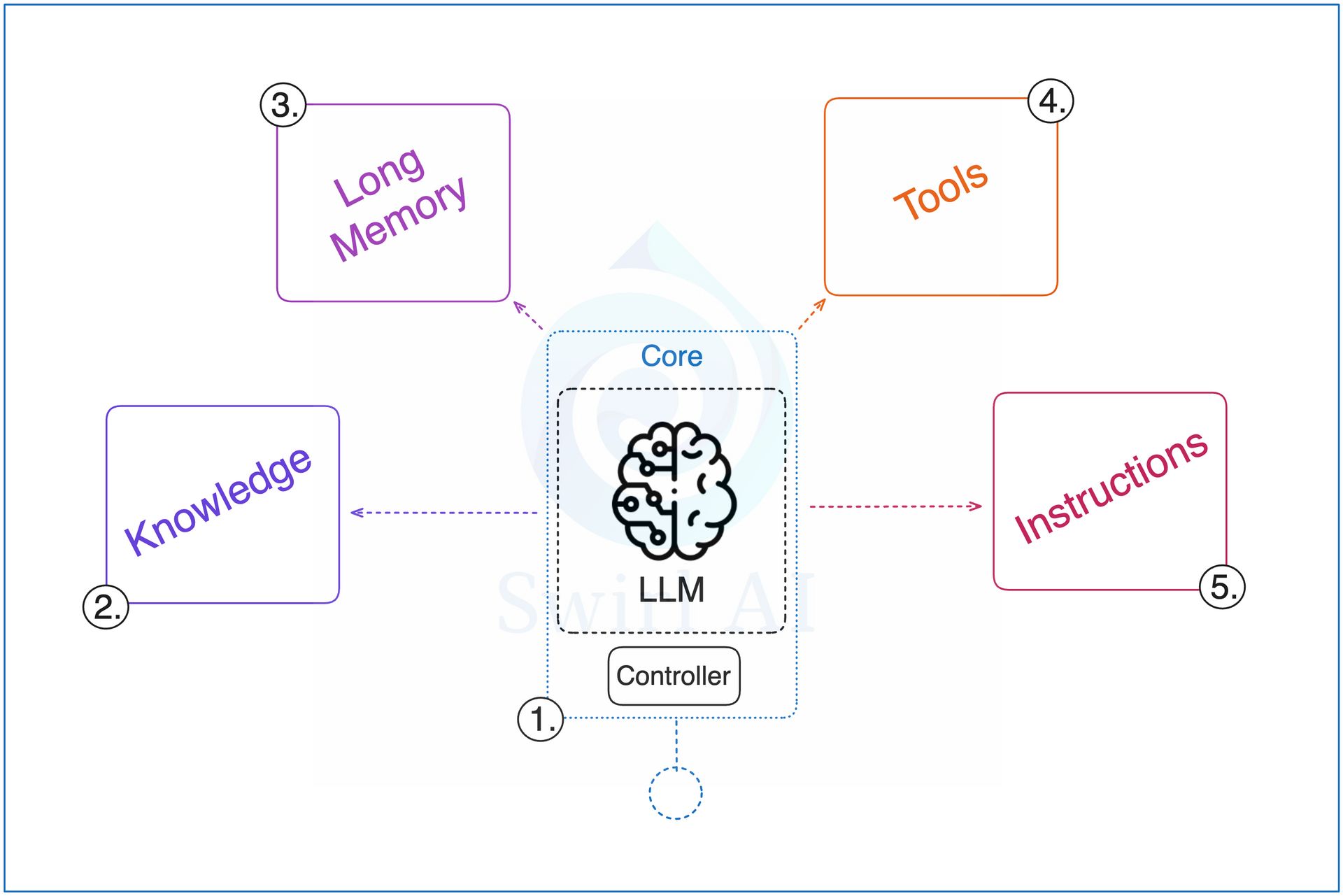
While short-term memory handles immediate conversations, long-term memory solves the problem of retaining critical information across multiple sessions. A simple implementation might use a text store like Google Docs. However, a more robust system will classify different types of memory:
User Memory: Stores preferences, interaction history, and other personalization details.
Domain Memory: Contains business rules, product information, and company policies.
Task Memory: Tracks the state of long-running processes, such as "what is the current phase of project X?".
Example of how long-term memory works:
When a user says, "I prefer to receive reports on Monday mornings," the agent writes to user memory: "User Preference: Wants reports on Monday mornings."
When an admin updates, "The new return policy is 30 days," the agent writes to domain memory: "Business Rule: Return policy is 30 days."
A critical challenge of long-term memory is updating and forgetting information. How does the agent know when information is outdated? This requires periodic memory validation and cleanup mechanisms, perhaps an automated process that runs nightly to check and refresh the agent's "memories."
3. Context From Tool Calling: Expanding Agent Capabilities

Tools give AI agents their real power, but they also come with the challenge of "context explosion." An often-overlooked aspect is the context from tool descriptions. How you describe a tool to the LLM directly influences its decision-making. A clear, detailed description with specific parameters helps the LLM call the tool more accurately.
Poor Description: "Search tool."
Good Description: "Product information search tool:
search_product(product_name: string). Use this tool to look up detailed information, pricing, and stock status of a specific product."
Furthermore, when tools are used in a "chain of tool use," where the output of one tool becomes the input for another, the context can become extremely complex. Managing these chains requires strict isolation and summarization strategies to prevent cross-contamination of context.
4. RAG - Retrieval-Augmented Generation

Retrieval-Augmented Generation (RAG) is an elegant solution for giving agents access to vast knowledge bases. To implement RAG effectively, one must consider its components in greater depth:
Chunking Strategy: Instead of fixed-size chunking, advanced methods like recursive chunking (based on sentence structure) or semantic chunking create more coherent and context-rich text segments.

Choosing an Embedding Model: Not all embedding models are created equal. Some models are optimized for specific languages, while others are better at capturing technical nuances. Choosing the right model is critical.

Advanced Retrieval Strategy: Instead of simple semantic search, Hybrid Search combines the power of traditional keyword search (like BM25) with semantic search to deliver more relevant results, especially for technical terms or proper nouns.

Re-ranking: After retrieving the top N documents, a smaller re-ranker model can be used to re-evaluate and sort them by relevance to the specific query before they are fed into the main LLM's context. This helps push the most critical information to the top.

Example: To answer a question about the "warranty policy for the X-15 laptop model," Hybrid Search would ensure results contain the exact keyword "X-15," while semantic search would find passages about "warranty" and "guarantee." A re-ranker would then push the passage containing both elements to the top.
5. Context Isolation: The Multi-Agent Approach

When tasks become overly complex, building a hierarchical agent team is the optimal solution. Instead of a flat group of agents, you can design a structure with a Coordinator Agent (manager), Supervisor Agents (team leads), and Worker Agents (specialists).
Example of an automated marketing team:
Coordinator Agent (CEO): Receives the high-level goal "Increase brand awareness for Product Y." It delegates tasks to supervisors.
Content Supervisor Agent: Responsible for the content strategy. It requests execution from worker agents.
Worker Agent - Research: Focuses solely on keyword research and competitor analysis. It handles the "dirty" context from the web and returns only a structured JSON file.
Worker Agent - Writing: Receives the JSON file from the Research Agent and focuses only on writing the article. Its context is completely clean, containing no HTML code or other noise.
This architecture ensures that complexity is encapsulated at each level, making the system incredibly robust and maintainable.
6. Context Summarization: Intelligent Information Compression
This strategy can be broken down into two main types:
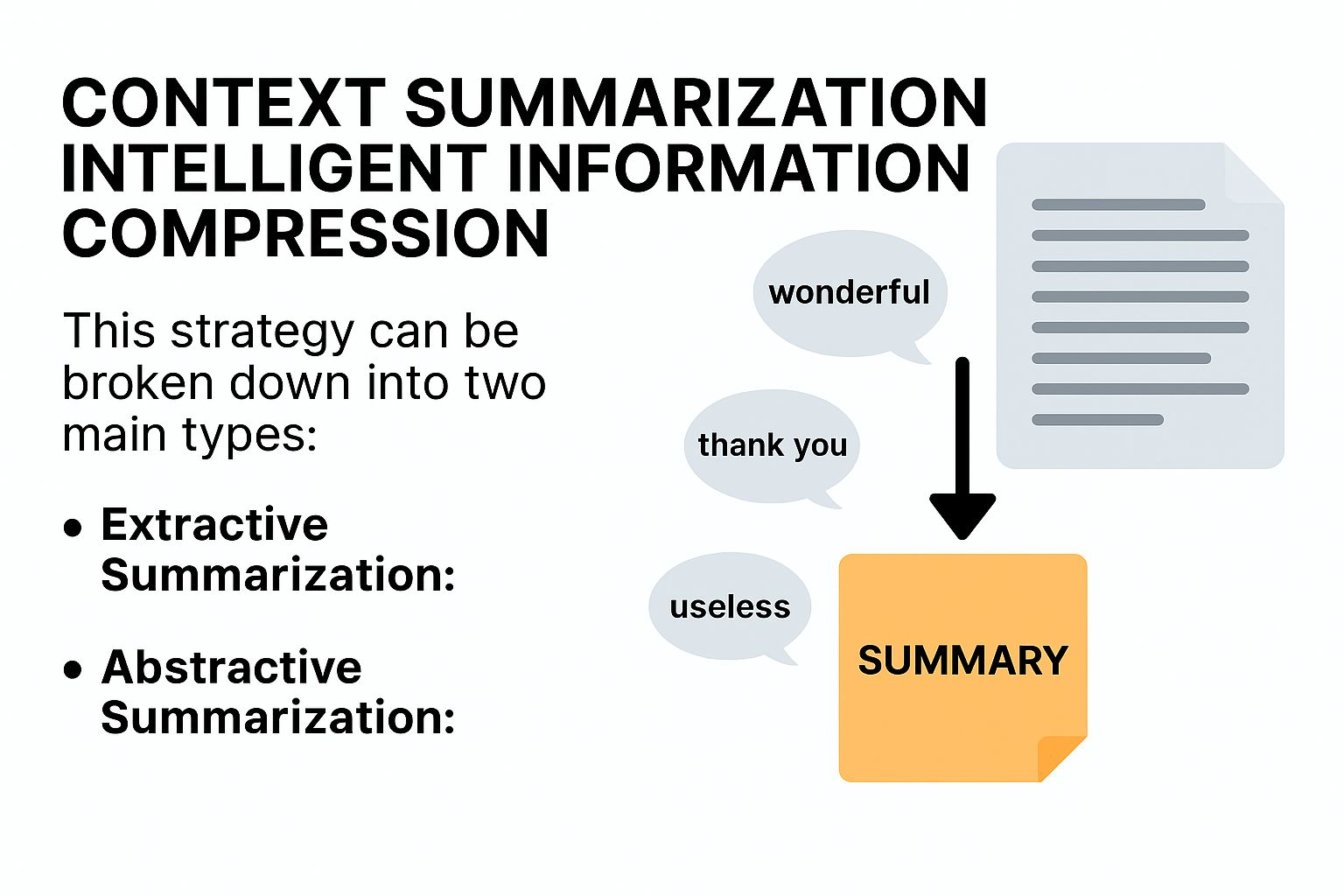
Extractive Summarization: This involves identifying and pulling out the most important sentences or phrases from the original text. This method is fast and ensures factual accuracy.
Abstractive Summarization: This involves the AI generating new sentences to summarize the main idea of the text. This method produces more natural and concise summaries but carries a risk of "hallucination" if not carefully controlled.
Example: To summarize a customer support email thread, extractive summarization might pull sentences like "Customer reported error X" and "We suggested solution Y." Abstractive summarization might write: "The customer encountered error X, and the team guided them through solution Y."
The choice of method depends on the application's requirements for speed and accuracy.
7. Context-Aware Routing & Staging: Managing Complex Workflows

To build complex and reliable workflows, we can borrow the concept of a Finite State Machine (FSM) from computer science. Each state in your workflow (e.g., new_order, payment_pending, shipped) has a clearly defined context and rules for transitioning to the next state.
Example of a routed order processing workflow:
State
new_order: Context contains only the order information. Agent A validates it and transitions to the next state.State
inventory_check: Context contains product IDs and quantities. Agent B calls the warehouse tool. If stock is sufficient, transition topayment_pending; otherwise, transition toout_of_stock.State
shipped: Context contains shipping information. Agent C calls the carrier's API and notifies the customer.
This approach turns a complex process into a series of simple, predictable, and debuggable steps.
8. Context Formatting: Making Information AI-Friendly

In addition to converting HTML to Markdown, formatting structured data is critically important. When working with data from APIs or databases, feeding it into the context as natural language is often inefficient. Instead, provide the data as clean, well-typed JSON.
Example: Instead of saying "The product is a T-Shirt, price is 250000 VND, 50 in stock," provide a JSON object:
{
"product_name": "Cotton T-Shirt",
"price": 250000,
"currency": "VND",
"stock": {
"quantity": 50,
"location": "Warehouse A"
}
}
This format helps the LLM parse and extract information with much higher accuracy.
9. Context Trimming: Strategic Information Reduction

Instead of trimming randomly, "smart trimming" techniques can be highly effective. One such technique is to use a cheaper, faster auxiliary AI model to perform a "relevance pre-pass."
Example: You have a 50-page document. Instead of feeding the entire thing to a GPT-4 model, you can first pass it through a smaller model like GPT-3.5-Turbo with the prompt: "From this document, identify and extract the 5 paragraphs most relevant to 'Q4 marketing strategy'." Then, you only need to feed these 5 paragraphs as context to the more powerful GPT-4 model. This technique significantly saves costs while maintaining high quality.
Common Pitfalls And How To Avoid Them

Even with these strategies, you can encounter pitfalls. "Context poisoning" could cause a medical support AI to give incorrect advice based on an outdated study it has memorized. "Context distraction" could make a legal assistant miss a critical clause in a contract because its context is cluttered with irrelevant emails. To overcome these, building processes for validation, cross-checking, and regular memory cleanup is mandatory, not optional.
Your Implementation Action Plan For Context Engineering
Applying these techniques should follow a methodical path.

Phase 1: Foundational Audit. This is the assessment stage. Map all data sources, analyze token usage logs to identify cost "hotspots," and interview users to find pain points in the current workflow.
Phase 2: Quick Wins. Focus on high-impact, low-effort solutions. Implement trimming, convert HTML to Markdown, and add simple short-term memory.
Phase 3: Systematic Improvements. This is where you re-architect the system. Implement multi-agent systems, set up RAG, and build automated summarization workflows. This phase requires significant time and resource investment.
Phase 4: Advanced Optimization. Once the system is operational, focus on fine-tuning. Build multi-level agent hierarchies, optimize embedding models, and create custom context management tools to achieve peak performance.
Conclusion: From AI User To AI Architect
Context Engineering represents a fundamental shift in how we build AI systems. It marks the transition from being an "AI user" (focused on writing prompts) to an "AI architect" (who designs the entire informational flow and memory of the system).
The nine strategies presented here are not independent formulas but building blocks that can be combined and customized to create sophisticated solutions. By mastering them, you are not only solving immediate problems like cost and accuracy but also building the foundation for the next generation of AI applications - those capable of autonomy, learning, and interacting with the world in a truly intelligent and persistent way. The future of AI is not in a perfect prompt, but in a perfect context architecture.
If you are interested in other topics and how AI is transforming different aspects of our lives or even in making money using AI with more detailed, step-by-step guidance, you can find our other articles here:
How useful was this AI tool article for you? 💻Let us know how this article on AI tools helped with your work or learning. Your feedback helps us improve! |
Reply