- AI Fire
- Posts
- 🥊 OpenAI Dropped GPT-5.2 (And It Makes Agents Useful Again)
🥊 OpenAI Dropped GPT-5.2 (And It Makes Agents Useful Again)
Benchmarks are cute. I tested the same prompts across GPT-5.2, Gemini 3, and Claude 4.5, and one of them actually finished the job.
Max Anh
December 15, 2025

TL;DR BOX
The newest ChatGPT model, GPT-5.2, feels like the new bar for reasoning. It hit 100% on AIME 2025 (no tools) and moved the needle on real coding work. More importantly: it’s getting more dependable in the places we actually care about day to day.
This ChatGPT model introduces a major leap in reliability, reducing hallucination rates to 6.2% and successfully executing complex, multi-step agentic workflows that previously failed. Its 256k token context window now supports 98% accuracy in data retrieval, making it viable for enterprise-grade financial and legal analysis.
Key points
Stat: GPT-5.2 scored 52.9% on the ARC-AGI-2 benchmark, a 3.1x improvement over GPT-5.1's 17% score.
Mistake: Using GPT-5.2 for simple queries; route basic tasks to GPT-5.1 to avoid the 40% higher cost.
Action: Use GPT-5.2 for visual extraction from charts + UI screenshots. That’s where the gap vs 5.1 is obvious.
Critical insight
The defining shift is reliability; GPT-5.2 crosses the threshold from "impressive demo" to "production-ready" by successfully completing long-chain workflows (like rebooking flights) that require 10+ sequential correct actions.
GPT-5.2 just crushed every benchmark. 🤯 Is the "AI Slowdown" officially dead? |
Table of Contents
I. Introduction: The "AI is Dead" Narrative Just Died
For months, I kept hearing “AI hit a wall”. Then GPT-5.2 dropped and… yeah, that take got a lot harder to defend.
Critics claimed that simply making models bigger had stopped working. They said the golden era of exponential growth was over and that the hype machine had finally run out of fuel.
This isn’t a small patch. If you’ve been doubtful about AI progress, that’s fair. But GPT-5.2 gives real reasons to pay attention. The new benchmarks don’t suggest things are slowing down. They show the opposite.
If you’ve felt that AI improvement was hitting a wall, this release clearly pushes back against that idea.
II. Which Benchmarks Matter and Where Did the New ChatGPT Model Pull Ahead?
Here are the benchmarks I personally care about, because they map to real work: coding, science reasoning, tool-use and long-context retrieval. The most important signal is ARC-AGI-2, where performance jumped from 17% to 52.9%, showing a real leap in abstraction and pattern learning.
Key takeaways:
Stronger performance on real-world coding, not toy problems.
Higher accuracy on PhD-level science and advanced math.
3.1x jump on ARC-AGI-2, a core generalization benchmark.
Clear lead on multi-step task execution (GDPval).
These results show GPT-5.2 improves where models usually fail: generalization, reliability and execution.
Benchmarks are the signal. The real proof comes later when you see the spreadsheet + tool-use demos.
Let’s start with the headline numbers, then explain why they matter more than typical benchmark improvements.
1. SWEbench Pro: The Real-World Coding Test
What this benchmark tests: SWEbench evaluates an AI's ability to solve actual GitHub issues from real open-source projects. These aren't synthetic coding puzzles; they're real bugs and feature requests submitted and resolved by human developers. The AI must understand the codebase, identify the problem, implement a fix and ensure it doesn't break anything else.
GPT-5.1 Thinking: Not disclosed.
GPT-5.2 Thinking: Hits 55.6% vs 50.8%. That’s not hype, those are real repo tasks.


The Business Implication: This ChatGPT model is now the most capable AI coding assistant for real-world development work. This directly translates to productivity gains for software teams and new capabilities for AI-powered coding startups. It isn't just solving LeetCode problems; it is navigating complex, unfamiliar codebases just like a senior engineer.
2. GPQA Diamond: Scientific Reasoning Without Tools
What this benchmark tests: The GPQA (Graduate-Level Google-Proof Q&A) Diamond subset contains PhD-level science questions spanning biology, chemistry and physics. The "without tools" constraint is critical: The model can't use calculators or search the web. It must reason purely from training knowledge.
GPT-5.1 Thinking: 88.1%.
GPT-5.2 Thinking: 92.4% (State-of-the-art).
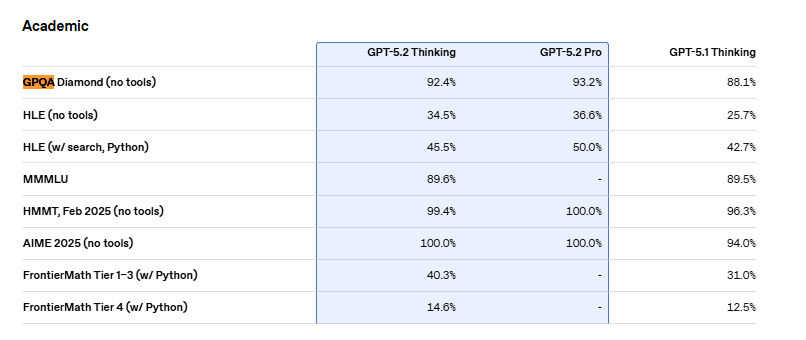

Why the 4% improvement matters: At this performance level, percentage point gains are increasingly difficult. Moving from 88% to 92% on PhD-level science shows a major capability improvement. GPT-5.2 is now competitive with domain experts for scientific analysis tasks that previously required human subject matter expertise.
Learn How to Make AI Work For You!
Transform your AI skills with the AI Fire Academy Premium Plan - FREE for 14 days! Gain instant access to 500+ AI workflows, advanced tutorials, exclusive case studies and unbeatable discounts. No risks, cancel anytime.
3. AIME 2025: The 100% Perfect Math Performance
What AIME tests: The American Invitational Mathematics Examination is an extremely difficult math competition for high school students. Problems require creative problem-solving, not just formula application.
Gemini 3.0 Pro: 95%.
Claude Opus 4.5: 92.8%.
GPT-5.2 Thinking: 100% (Aced every question).

The Significance: Not a single error. Not one computational mistake or logical oversight. This is the first time a ChatGPT model has achieved perfect performance on AIME 2025 (even with other AI models). It indicates a qualitative leap in logical reasoning capabilities.
4. ARC-AGI 2: The Benchmark That Defines Real Intelligence
This is where GPT-5.2's performance becomes genuinely shocking.
GPT-5.1 Thinking: 17%.
GPT-5.2 Thinking: 52.9% (State-of-the-art).

Source: ARC-AGI 2.
That is a 3.1x improvement.
What makes ARC-AGI different: Created by François Chollet, ARC-AGI is designed to test genuine generalization, the ability to learn abstract patterns from minimal examples and apply them to novel situations. It is designed to resist memorization. ARC-AGI is one of the tougher generalization tests because it’s designed to punish memorization.
The Efficiency Leap: One year ago, a preview model scored 88% but cost an estimated $4,500 per task. Today, GPT-5.2 achieves nearly the same performance at $11 per task. That is a 390x efficiency improvement in one year.

Source: Arc Prize
5. GDPval: Real-World Knowledge Task Execution
What GDPval tests: Real-world knowledge tasks requiring multi-step reasoning, tool use and complex workflow execution.
Claude Opus 4.5: 59.6% (Second place).
GPT-5.2 Thinking: 70.9% (Leader).
The 11.3 percentage point gap is massive. This isn’t a marginal improvement. It is a dominant market-leading capability.

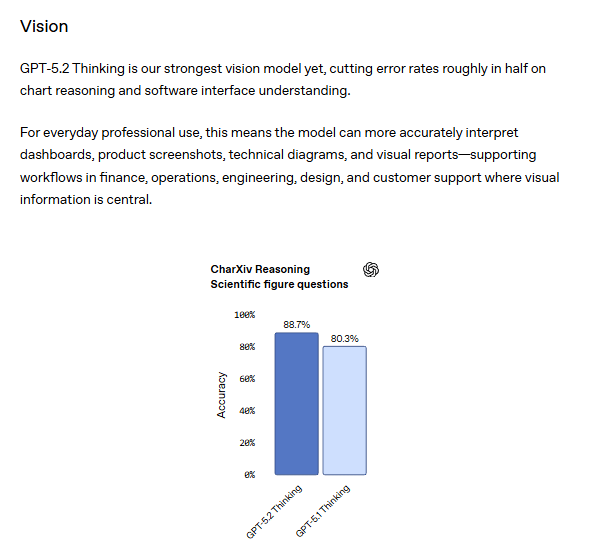
III. Why Is GPT-5.2’s Visual Reasoning A Breakthrough?
GPT-5.2 can now interpret charts, technical diagrams and UI screenshots at near-human accuracy. On vision, GPT-5.2 Thinking improves a lot: CharXiv Reasoning (w/ Python) 88.7% vs 80.3% and ScreenSpot-Pro (w/ Python) 86.3% vs 64.2%. This turns visual understanding from a demo feature into a production-ready capability.
Key takeaways:
Reads charts and scientific figures with high accuracy.
Understands software UIs from screenshots.
Can navigate apps, fill forms and extract visual data.
Enables automation of analyst and operations work.
Visual reasoning is now reliable enough to replace manual inspection in many workflows.
Most benchmark discussions focus on text and code. But GPT-5.2’s visual reasoning improvements may be its most economically significant upgrade.
1. Chart Reasoning: Scientific Figure Understanding
GPT-5.1 Thinking: 80%.
GPT-5.2 Thinking: 88%.
Why this matters economically: Analysts, researchers and consultants spend hours extracting insights from visual data. The new ChatGPT model can now do this at near-human accuracy, dramatically faster and at a lower cost.
2. ScreenSpot Pro: GUI Screenshot Understanding
GPT-5.1 Thinking: 64%.
GPT-5.2 Thinking: 86%.
What this measures: The ability to understand user interfaces (identifying buttons, input fields and navigation elements just from screenshots).
The Practical Application: Imagine a ChatGPT model that can actually use software on your behalf (scheduling meetings, filling forms, navigating enterprise apps). Moving from 64% to 86% makes this viable for production use. It crosses the threshold from "demo" to "reliable automation".

3. The Motherboard Analysis Demonstration
This kind of visual grounding can help with things like QA checks and troubleshooting. For medical imaging, it’s still “assist + human review”, not autopilot.
GPT-5.1: Identified 4 components with poor accuracy.
GPT-5.2: Identified dozens of components (RAM slots, CPU socket, PCIe slots, power connectors) with precise bounding boxes.

GPT-5.2 shows much better image understanding.
The Business Applications: Quality control in manufacturing, medical imaging analysis (X-rays, MRIs) and automated technical support diagnostics are now feasible with this ChatGPT model.
IV. Long Context Reasoning: The 256K Token Reality Check
Context window size has been an arms race but size without capability is meaningless. What matters is reasoning across that context.
The "Needle in Haystack" Test (MRCRv2)
This benchmark embeds specific pieces of information ("needles") within massive documents ("haystacks") and tests whether the model can find and use them.
Four Needles Test (256K tokens):
GPT-5.1 Thinking: 42% accuracy.
GPT-5.2 Thinking: 98% accuracy.

What this means: GPT-5.1 could accept 256K tokens but it couldn’t reason across them reliably. At 42% accuracy, it was effectively unreliable. GPT-5.2 at 98% accuracy fundamentally changes what is possible. You can now confidently give it entire codebases, complete legal contracts or full years of company data and trust the analysis.
V. The Practical Demonstration: Real-World Work Tasks
OpenAI didn't just show benchmarks. They demonstrated GPT-5.2 handling actual professional tasks with production-ready quality.
1. Workforce Planning Model Creation
I ran this exact workforce prompt twice. First run failed. Second run took longer but the spreadsheet was exec-ready.
The Prompt:
Create a workforce planning model: headcount, hiring plan, attrition and budget impact. Include engineering, marketing, legal and sales departments. GPT-5.2 Result: A professionally formatted Excel file with clear visual hierarchy, color coding and logical organization. Ready to present to executives without additional formatting work.

GPT-5.1 Result.

GPT-5.2 Result.
The Value: HR professionals charge $100-200/hour for this. GPT-5.2 delivers it in minutes.
2. Cap Table Management (High-Stakes Accuracy)
The Prompt:
Create a capitalization table tracking equity ownership across multiple funding rounds. GPT-5.1 Result: Incorrect calculations. Failed liquidation preferences.

GPT-5.1 Result.
GPT-5.2 Result: All calculations correct. Complete data population. Accurate equity distribution.

GPT-5.2 Result.
Why it matters: Cap tables involve millions of dollars. Getting them wrong has catastrophic consequences. The difference between "mostly right" and "completely right" is the difference between usable and unusable.
3. The Ocean Wave Simulation (Coding)
The Prompt:
Create a single-page app in a single HTML file with the following requirements:
- Name: Ocean Wave Simulation
- Goal: Display realistic animated waves.
- Features: Change wind speed, wave height, lighting.
- The UI should be calming and realistic.After testing this prompt in 2 models (GPT-5.1 and 5.2), I’m kind of surprised that:
GPT-5.2 Result: A fully functional, visually stunning ocean simulation in a single HTML file. It included realistic wave physics, dynamic lighting controls and a polished UI. It looked perfect with just one prompt, no bugs to fix, no adjustments needed.

GPT-5.1 Result: The first time I tested it, the result was completely disappointing, just a blank screen with the name of the app on the edge. After taking a screenshot and reporting this error, it worked but the result was like a 2D simulator from the 80s (even worse).

The Implication: GPT-5.2 understands how to build complete applications, integrating physics, graphics rendering, UI and interactivity from a single prompt.
VI. How Reliable Is GPT-5.2 In Practice?
GPT-5.2 reduces hallucinations to 6.2%, down from 10-15% in earlier generations. That change shifts how teams use AI: from full human review to spot-checking. The economic impact comes from fewer failures and faster throughput.
Key takeaways:
Much lower hallucination rate.
Fewer silent errors in long workflows.
Safer for high-stakes tasks like finance and ops.
Moves AI from “assistive” to “dependable.”
Reliability, not raw intelligence, is the real upgrade here.
Benchmark performance means nothing if the model lies.
GPT-5.2 Thinking: 6.2% hallucination rate.

That number might seem high (1 in 16 responses) but context matters. OpenAI claims hallucination/error rates dropped to 6.2% in their evals.
That’s the real story: fewer silent wrong answers. This efficiency shift is economically significant.
VII. Can GPT-5.2 Execute Long, Multi-Step Workflows?
Yes. On tool-use benchmarks like TAU-2, GPT-5.2 achieved 98.7% success on tasks requiring 7-10 sequential actions. GPT-5.1 failed at these workflows. GPT-5.2 maintains state, uses tools correctly and finishes the job.
Key takeaways:
Handles long chains of dependent actions.
Uses APIs and tools without breaking context.
Solves real customer support and ops scenarios.
Enables serious automation beyond chat.
This is what unlocks real AI agents, not just smarter chatbots.
The TAU-2 benchmark tests how well AI can use external tools (APIs, databases) to complete tasks.
Customer Support Use Case:
GPT-5.1 Thinking: 47% success.
GPT-5.2 Thinking: 98.7% success.

The Scenario: A customer has a complex flight issue involving delays, missed connections, lost bags and medical requirements. Resolution requires 7-10 sequential tool calls (flight status API, booking database, baggage claim system).
The prompt:
My flight from Paris to New York was delayed and I missed my connection to Austin. My checked bag is also missing and I need to spend the night in New York. I also require a special front-row seat for medical reasons. Can you help me?
The Impact: GPT-5.1 failed on complex workflows. GPT-5.2 handles them reliably. This means call centers can automate dramatically more support volume, reserving humans for only the truly exceptional cases.
VIII. The Pricing Reality: Is It Worth It?
GPT-5.2 is about 40% more expensive than GPT-5.1 but delivers 2-3x gains in reasoning, visual analysis, tool use and long-context accuracy. For simple tasks, cheaper models still win. For complex work, GPT-5.2 has a positive ROI.
Key takeaways:
Use cheaper models for simple queries.
Route complex, high-value tasks to GPT-5.2.
Cost increase is smaller than the capability gain.
Best results come from model routing.
The pricing only hurts if you use it for the wrong tasks.
GPT-5.2 is significantly more expensive than 5.1.
Input Tokens: $1.75 per million (40% increase).
Output Tokens: $14 per million (40% increase).

Source: OpenRouter.
The Value:
ARC-AGI Performance: 3.1x improvement.
Visual Reasoning: 1.34x improvement.
Tool Use: 2.1x improvement.
Long Context: 2.3x improvement.
If your use case benefits from any of these, you are getting a 2-3x capability increase for a 40% cost increase. That is positive ROI.
My Rule: if the task is simple, don’t pay for expensive thinking. If it’s a long doc, visual extraction or a workflow that must finish, then GPT-5.2 earns its cost.
IX. The Competitive Landscape & Prediction Markets
Prediction Markets Signal: On platforms like Polymarket, the probability of OpenAI having the best coding model on Jan 1, 2026, jumped from 57% to 80% after the GPT-5.2 release (12/12/2025). Smart money is betting heavily on this model's dominance.

Source: Polymarket.
Enterprise Validation: Box tested GPT-5.2 and found dramatic improvements in speed (50%+ faster time to first token) and accuracy (moving from 59% to 70% on complex extraction). For enterprise workflows, speed and accuracy translate directly to cost savings.

Source: Box.
X. How Does GPT-5.2 Compare To Gemini 3.0 Pro And Claude Opus 4.5?
Here’s how I’d route tasks based on what we’re seeing so far: GPT-5.2 leads in reasoning, complex coding, visual UI understanding and long workflows. Gemini remains strong in native video and audio tasks. Claude still wins on conversational tone and explanations. Each model has a role.
Key takeaways:
GPT-5.2 is the strongest executor.
Gemini excels in multimodal media tasks.
Claude feels more natural for writing and explanations.
No single model wins every category.
GPT-5.2 is the best “worker,” even if it’s not the best conversationalist.
The AI landscape is no longer a monopoly; it is a three-way standoff. With the release of GPT-5.2, we finally have the metrics to compare the "Big Three" directly. Based on independent evaluations and reported benchmarks, here is how they stack up.
1. The Reasoning Gap (Math & Science)
When it comes to hard logic, GPT-5.2 has pulled ahead.
AIME (Math): GPT-5.2 scored close to perfect at 100%, leaving Gemini 3.0 Pro (96%) and Claude 4.5 Opus (91%) behind.
GPQA (Science): GPT-5.2 holds the crown at 90%, while competitors are still trying to break the 90% barrier consistently (except Gemini 3.0 Pro with 91%).
Verdict: If your task involves complex calculation or scientific derivation, GPT-5.2 is the undisputed leader.
2. The Coding Battlefield
This is the most contested ground.
GPT-5.2: Dominates SWEbench Pro with a 5% jump over previous SOTA. It excels at multi-file architecture and debugging complex repositories.
Claude 4.5 Opus: Still holds the "Vibes" title. Many developers prefer Claude for one-shot scripts and explanations because its tone feels more natural but it loses out on raw, complex execution metrics.
Gemini 3.0 Pro: Fast and efficient but recent evaluations suggest it struggles more with maintaining context in massive, legacy codebases compared to the other two.
Verdict: Use GPT-5.2 for building and architecture; use Claude for explanations and documentation.
Creating quality AI content takes serious research time ☕️ Your coffee fund helps me read whitepapers, test new tools and interview experts so you get the real story. Skip the fluff - get insights that help you understand what's actually happening in AI. Support quality over quantity here!
3. The Multimodal Edge
Gemini 3.0 Pro: Google's native multimodal training has historically given it an edge in video and audio integration. It feels seamless.
GPT-5.2: With the new ScreenSpot score of 86% and chart reasoning at 88%, OpenAI has neutralized Google's advantage. It can now read UI and technical diagrams with startling accuracy.
Verdict: It is a draw. Gemini is better for video/audio native tasks; GPT-5.2 is better for static image and UI analysis.
4. Human Preference (The "Vibes" Test)
Interestingly, on LMArena WebDev, Claude Opus 4.5 (thinking) is still #1 at 1519, with GPT-5.2-high at 1486.
Why? Claude feels more "human". It is often more concise and less robotic in conversation. GPT-5.2 is a better worker but Claude might still be a better conversationalist.

Source: LM Arena
XI. My Honest Thoughts About GPT-5.2
The fast release of GPT-5.2 shows that OpenAI is pushing hard after the successful launch of Google’s Gemini 3.0. After I ran the same prompt in two models, I was impressed by the output quality of this ChatGPT model but the hype felt familiar (similar to the GPT-5 launch) and made me question whether this is a true leap or partly a marketing boost.
I did notice speed issues in some tasks. For Workforce Planning Model Creation, GPT-5.1 produced a simpler result quickly (4-5 minutes), while GPT-5.2 took much longer. My first run failed after 16 minutes and the second took over 14 minutes, though the final output was far better. The quality improved but at the cost of speed.

My first failure with GPT-5.2.
That slowdown didn’t happen in coding tasks. In the Ocean Wave Simulation, GPT-5.2 was just as fast, sometimes faster than GPT-5.1, with clearly stronger results.
Overall, I think GPT-5.2 can compete directly with Gemini 3.0 on general tasks. However, for pure coding workflows, Claude 4.5 Opus still seems to have an edge.
XII. Conclusion: The Exponential Curve Continues
The conversation around AI hitting development walls just got dramatically quieter. GPT-5.2 isn't just an incremental update. It is proof that ChatGPT models are still improving very fast.
For businesses, the competitive advantage now comes from deployment strategy, not just access. Everyone has the tools; winners will integrate them effectively. For developers, the bottleneck shifts from "what's technically possible" to "what workflows should we automate".
GPT-5.2 is impressive. But if history teaches us anything about exponential curves, it is probably not as remarkable as what comes next.
Pick one workflow you hate (reports, spreadsheets, forms). Run it end-to-end in GPT-5.2. If it fails, you found your boundary.
If you are interested in other topics and how AI is transforming different aspects of our lives or even in making money using AI with more detailed, step-by-step guidance, you can find our other articles here:
Overall, how would you rate the LLMs series? |
Reply