- AI Fire
- Posts
- 🧠 Forget Traditional RAG! This New Agentic RAG UNDERSTANDS
🧠 Forget Traditional RAG! This New Agentic RAG UNDERSTANDS
The secret is combining vector search with Knowledge Graphs, giving your AI the power to reason, not just retrieve
Max Anh
July 15, 2025

🧠 What Kind of Question Breaks Your RAG Agent?RAG agents are great at some queries but fail miserably at others. Which type of question gives your "chat with your docs" AI the most trouble? |
Table of Contents
RAG 2.0 is Here: How to Build an AI Agent That Actually Understands Your Data (With Knowledge Graphs!)
Forget everything you thought you knew about Retrieval-Augmented Generation (RAG) systems. We're not in Kansas anymore, Dorothy.
Look, I've been down the RAG rabbit hole for months, testing every strategy under the sun - from simple vector search to complex chunking methods. And I keep coming back to the same frustrating conclusion: traditional RAG is like trying to have a serious conversation with someone who can only respond by reading you random, out-of-context excerpts from a Wikipedia article. Sure, the information is factually correct but it lacks understanding, connection and the ability to reason. It’s about as flexible as a brick wall.
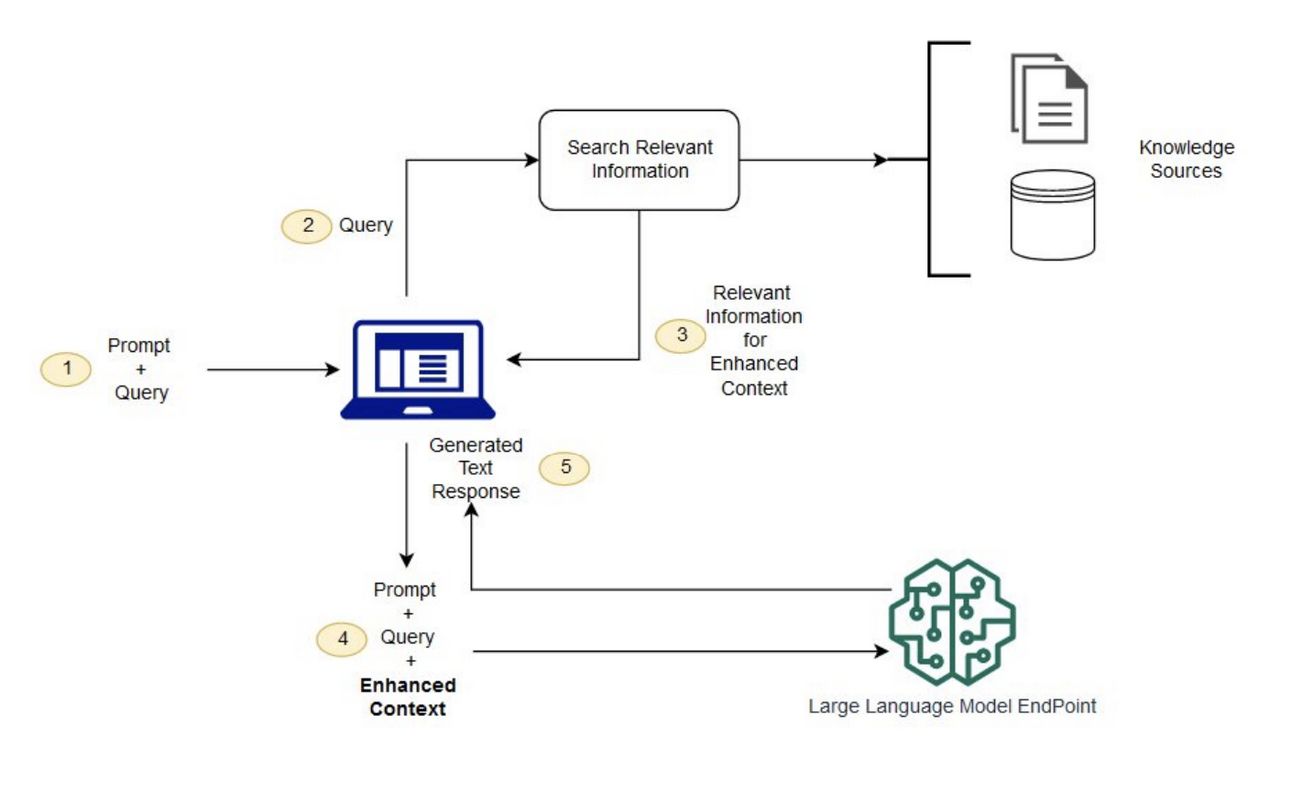
That's why I am so incredibly excited to share something that has been consuming my nights and weekends - a complete game-changer in how we build AI agents that work with information. It’s a system that combines the best of both worlds: the lightning-fast semantic search of Agentic RAG and the deep, relational understanding of Knowledge Graphs.
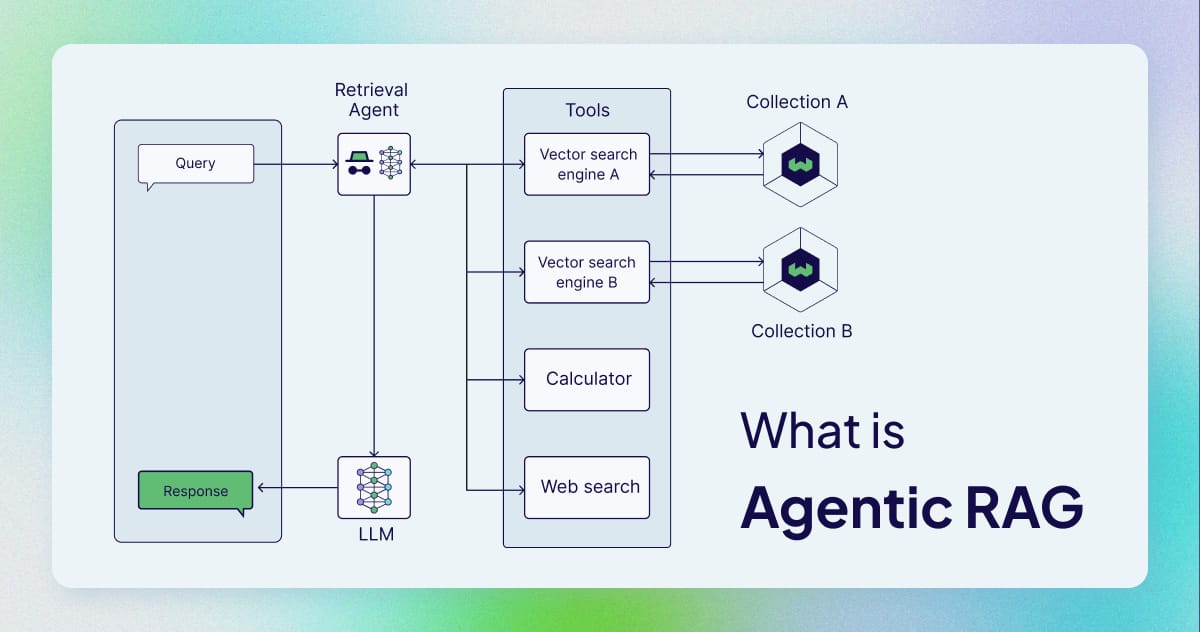
Think of it this way:
A traditional RAG system gives your AI a photographic memory (the vector database). It can recall facts perfectly.
This new Agentic RAG system gives your AI a photographic memory and the ability to connect the dots between those facts (the knowledge graph).
It's the difference between having a really good filing cabinet and having a brilliant research assistant who has not only read every document in the cabinet but also understands how every single person, company and concept mentioned in those documents relates to everything else.
Today, I'm giving you the complete system - the code, the step-by-step setup instructions and all the insider tricks I've learned while building this beast. Ready to build an AI agent that doesn't just search your data but actually understands it? Let's begin.
Part 1: Why Traditional RAG is Like Using a Flip Phone in 2024
Before we jump into building the future with Agentic RAG, let's take a moment to understand why the present is so frustrating. The traditional RAG process, which has powered most of the "chat with your documents" apps we've seen, works like this:
You take your documents, chop them up into small "chunks", create a mathematical "embedding" for each chunk and store them all in a vector database.
A user asks a question. You embed their question and search the database for the chunks that are most mathematically similar.
You then stuff these chunks into a prompt and tell a language model, "Here, use this context to answer the question".
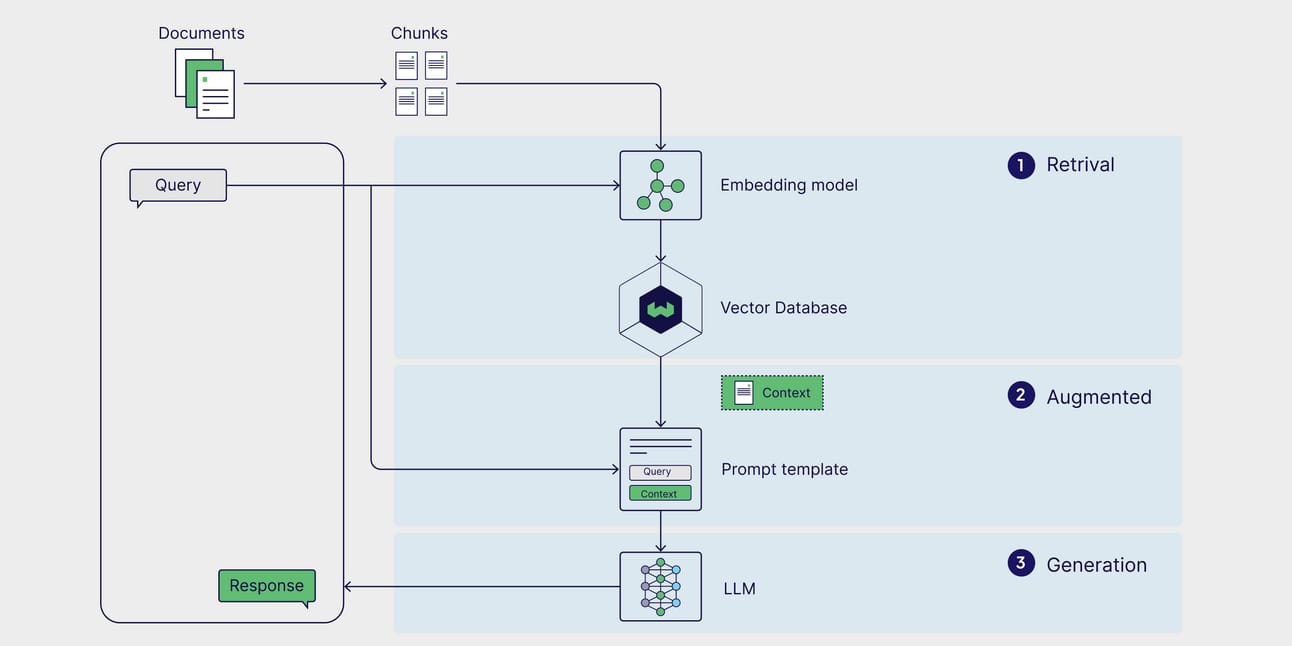
The language model is then forced to respond using only the context it was given, whether that context is actually relevant or not.
The problem with this approach is that your AI agent is basically a very expensive and inflexible search engine. It has no autonomy. It can't decide that the initial search results are bad and try a different approach. It can't explore the relationships between different concepts. It can't reason. This is the fundamental limitation that Agentic RAG overcomes.
This is where Agentic RAG, combined with Knowledge Graphs, changes the game entirely. In this new system, the AI agent is in charge. It can analyze the user's question and then decide on the best strategy to find the answer.
It can perform a traditional vector search if the question is about a specific fact.
It can traverse a knowledge graph if the question is about the relationship between two things.
Or, for a complex query, it can combine both approaches, using the vector search to find initial entities and then using the graph to explore their connections.
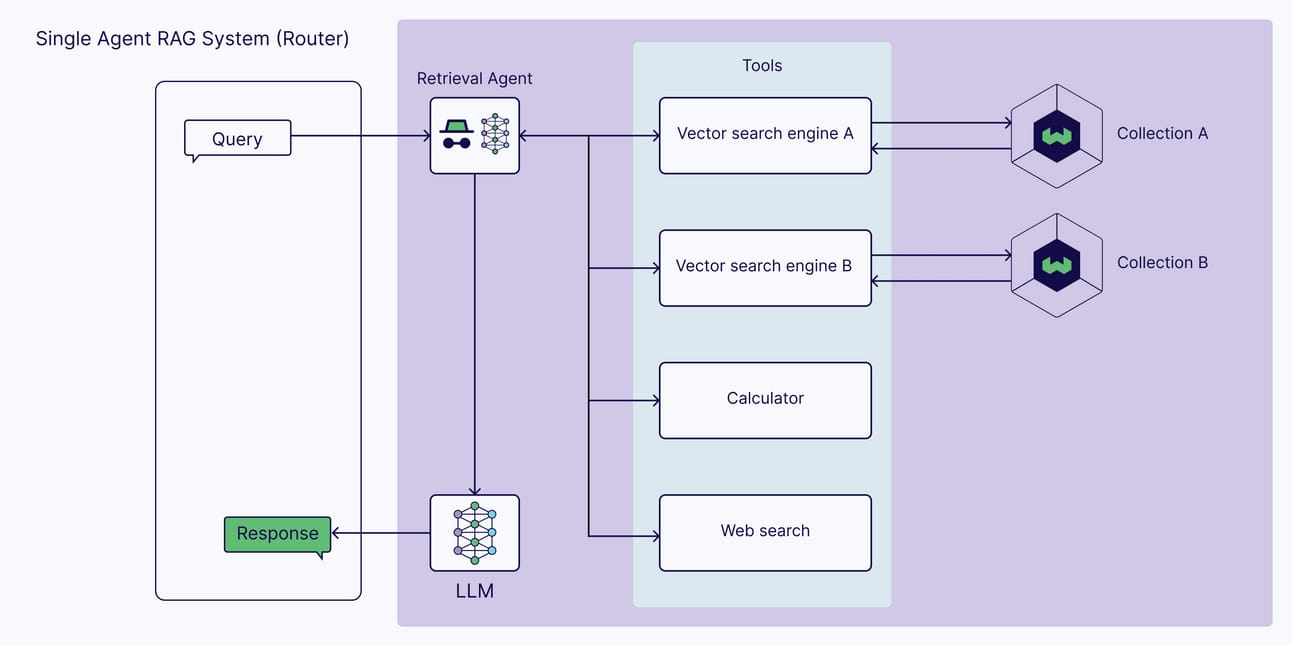
A Real-World Example: Instead of just finding separate documents about "Microsoft" and "OpenAI", your new agent can understand that Microsoft is OpenAI's exclusive cloud provider, that they have a multi-billion-dollar strategic partnership and that this relationship directly impacts their competitive strategies against other companies. It's the difference between having a scattered list of facts and having actual, interconnected knowledge.
Learn How to Make AI Work For You!
Transform your AI skills with the AI Fire Academy Premium Plan - FREE for 14 days! Gain instant access to 500+ AI workflows, advanced tutorials, exclusive case studies and unbeatable discounts. No risks, cancel anytime.
Part 2: The Tech Stack That Makes This Possible
Here’s a look at the powerful (and mostly open-source) tools that power this knowledge-graph-enhanced monster.
🧠 Core Agent Framework: Pydantic AI
This is my absolute favorite Python library for building structured, reliable and predictable AI agents. It allows you to define the exact format of the AI's output, which is crucial for building dependable systems.

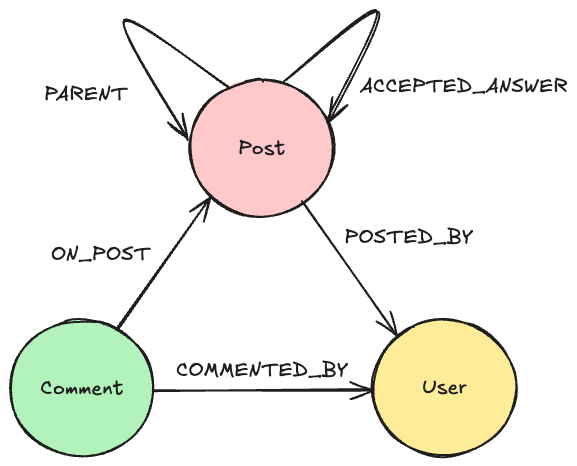
We use Graphiti to define the structure of our knowledge graph and Neo4j as the powerful, industry-standard database for storing and querying the relationships between our data points.
🔍 Vector Database: PostgreSQL + pgvector
This is a clever choice. Instead of running a separate, dedicated vector database, we use the popular and robust PostgreSQL with the pgvector extension. This essentially turns a traditional SQL database into a high-performance vector database. It's like having a sports car that also happens to be a submarine.

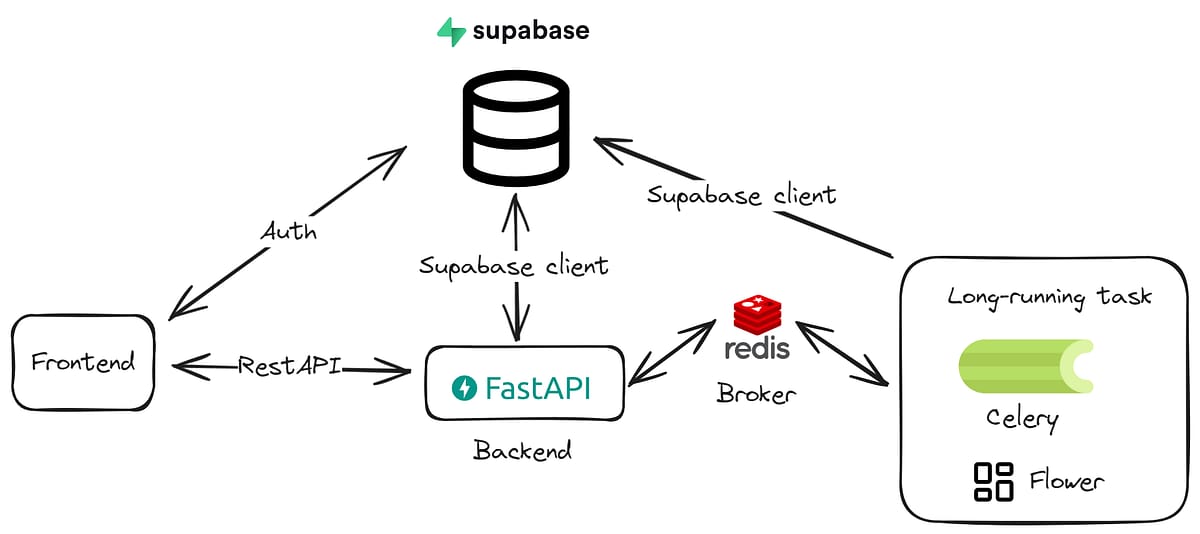
⚡ API Framework: FastAPI
We use FastAPI to build a simple, fast and modern API that allows us to communicate with our agent.
The system is designed to be flexible. It can work with any OpenAI-compatible provider, including OpenAI itself, local models via Ollama or Google's Gemini.

The beauty of this stack is that everything works together seamlessly and you can run the entire thing locally on your own machine if you prioritize privacy and control. There is no vendor lock-in and no black boxes - just pure, customizable AI power.
Part 3: Setting Up Your Agentic RAG System (Step-by-Step)
Alright, let's build this thing. I've made the code available and the process as painless as possible but there are a few moving parts we need to set up correctly.
Prerequisites (The Boring But Necessary Stuff)
Before we start, make sure you have a few things installed on your computer:
Python 3.11 or higher (the programming language we'll be using).
A PostgreSQL database. I will show you how to set up a free one with a service called Neon.
A Neo4j database. This will be our knowledge graph engine.
An API key for your chosen Large Language Model (LLM) provider (like OpenAI).

Step 1: Get the Code and Set Up Your Environment
First, you'll need to grab the code from the GitHub repository and set up your Python environment. This ensures that all the necessary libraries are installed in an isolated space.
Action: Open your terminal or command prompt and run the following commands:
# Create a Virtual Environment
cd path\to\your\project # Windows
# or
cd /path/to/your/project # macOS/Linux
then run
python -m venv venv
or, if your system uses python3:
python3 -m venv venv
# Activate virtual environment
python -m venv venv # python3 on Linux
source venv/bin/activate # On Linux/macOS
# or
venv\Scripts\activate # On Windows (Command Prompt)
.\venv\Scripts\Activate.ps1 # On Windows (PowerShell)
# Install dependencies
pip install -r requirements.txt
Create a virtual environment

Activate the virtual environment
Install dependencies
Step 2: Database Setup (PostgreSQL with Vector Superpowers)
We're using PostgreSQL with the pgvector extension, which is a brilliant way to get the power of a vector database without adding another piece of infrastructure.
Action: Setting up with Neon (Recommended)
Go to Neon and create a free account. Their free tier is more than powerful enough for this project.
Create a new project. Neon will provide you with a database connection URL. This is a crucial piece of information that you will need in a moment.
In the GitHub repository you downloaded, find the
sql/folder. There will be a SQL file inside. Copy the entire contents of this file.
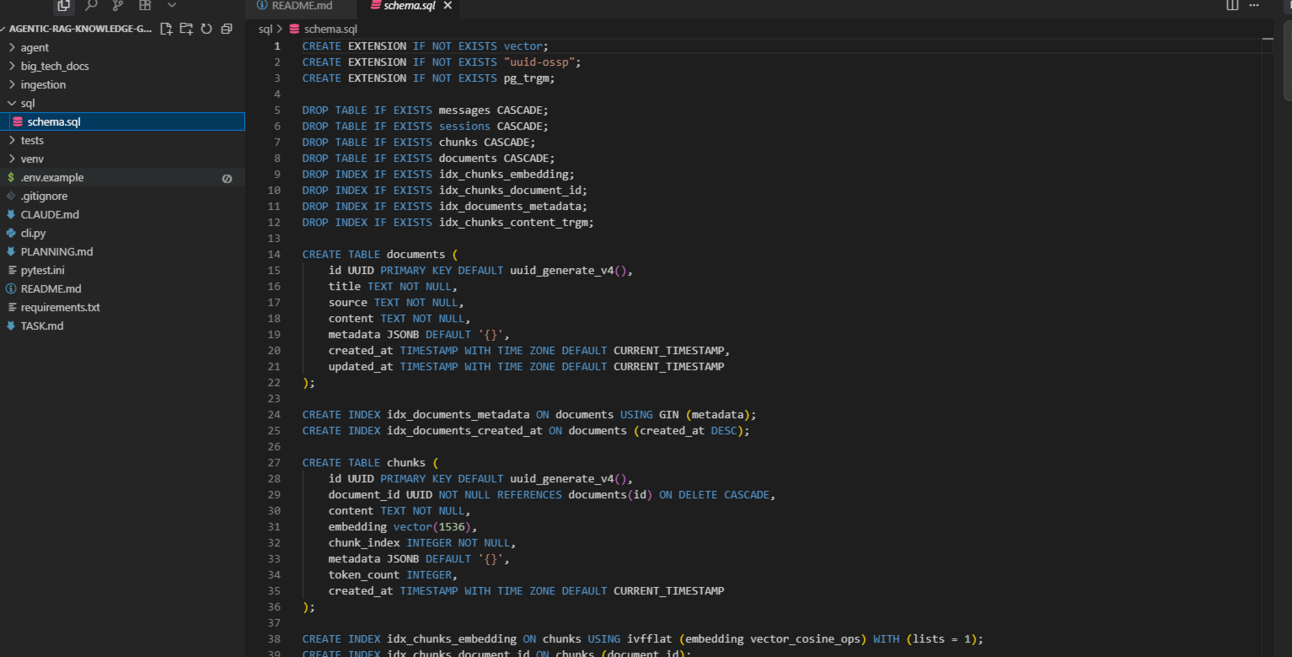
Go back to Neon's dashboard, find their SQL editor, paste the SQL code into it and run it. This will create the necessary tables and enable the vector extension in your database.
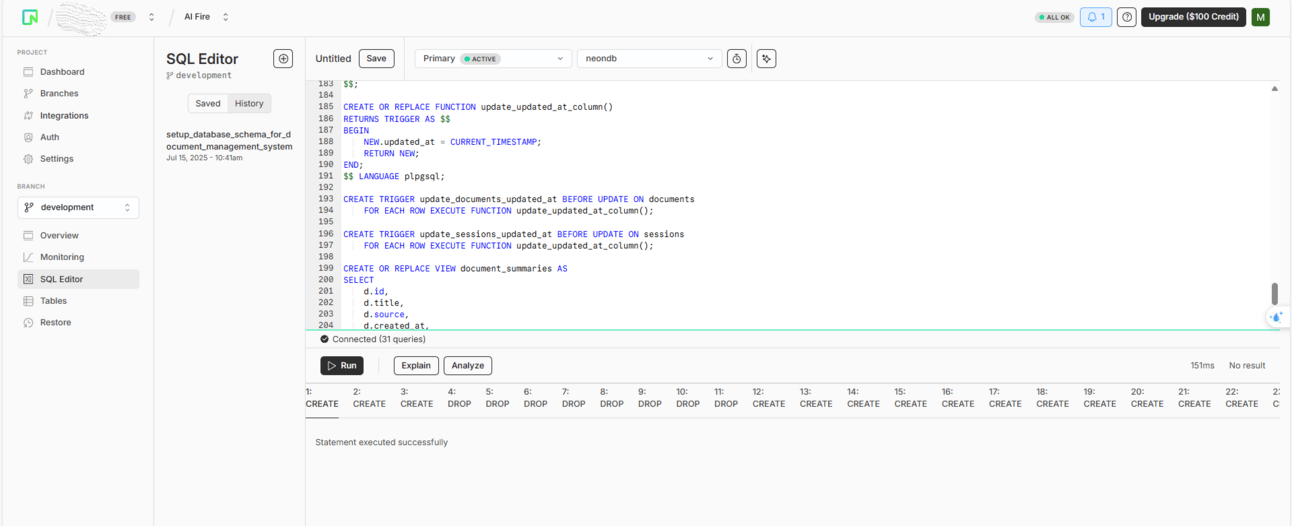
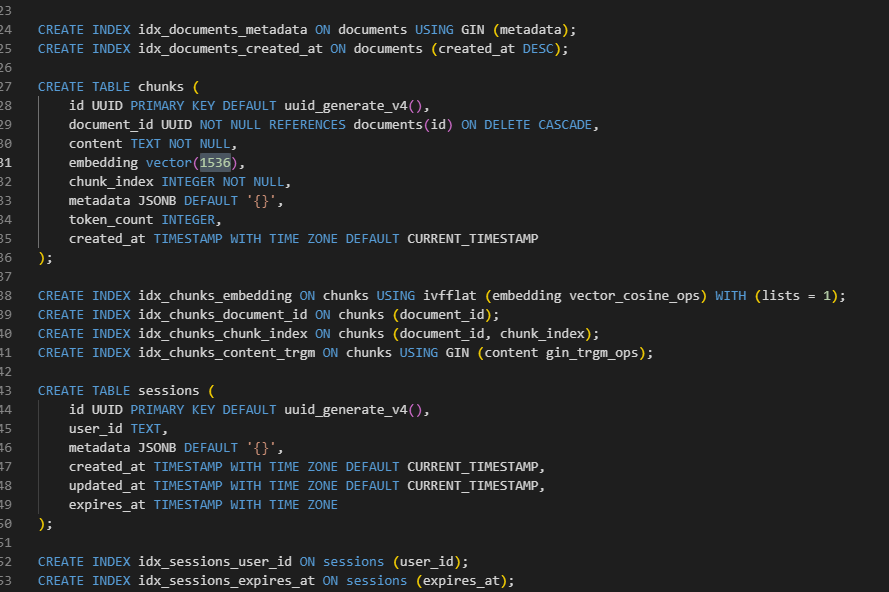
Important Note: The provided SQL code is set up for OpenAI's text-embedding-3-small model, which has vector dimensions of 1536. If you are using a different embedding model, you will need to find the line in the SQL file that says vector(1536) and change that number to match the dimensions of your chosen model.
Step 3: Neo4j Setup (Your Knowledge Graph Engine)
You have two main options for setting up the knowledge graph database for your Agentic RAG system.
Option A (Easiest): Use a Curated Local AI Package. There are pre-built packages of open-source AI tools that include Neo4j. This is a great option if you want everything running locally with minimal setup.
Option B (Standard): Install Neo4j Desktop. You can download the Neo4j Desktop application from their official website and follow the setup instructions. It's a straightforward installation process.
Action: Whichever option you choose, you will need to get the username and password for your Neo4j database for the next step.
Step 4: Environment Configuration (The Secret Sauce)
This is where you tell your application how to connect to all the different services.
Action: In the project folder, find the file named .env.example. Make a copy of this file and rename it to just .env. Now, open the .env file and fill in all of your specific details:
# Database Configuration (example Neon connection string)
DATABASE_URL=postgresql://username:[email protected]/neondb
# Neo4j Configuration
NEO4J_URI=bolt://localhost:7687
NEO4J_USER=neo4j
NEO4J_PASSWORD=your_password
# LLM Provider Configuration (choose one)
LLM_PROVIDER=openai
LLM_BASE_URL=https://api.openai.com/v1
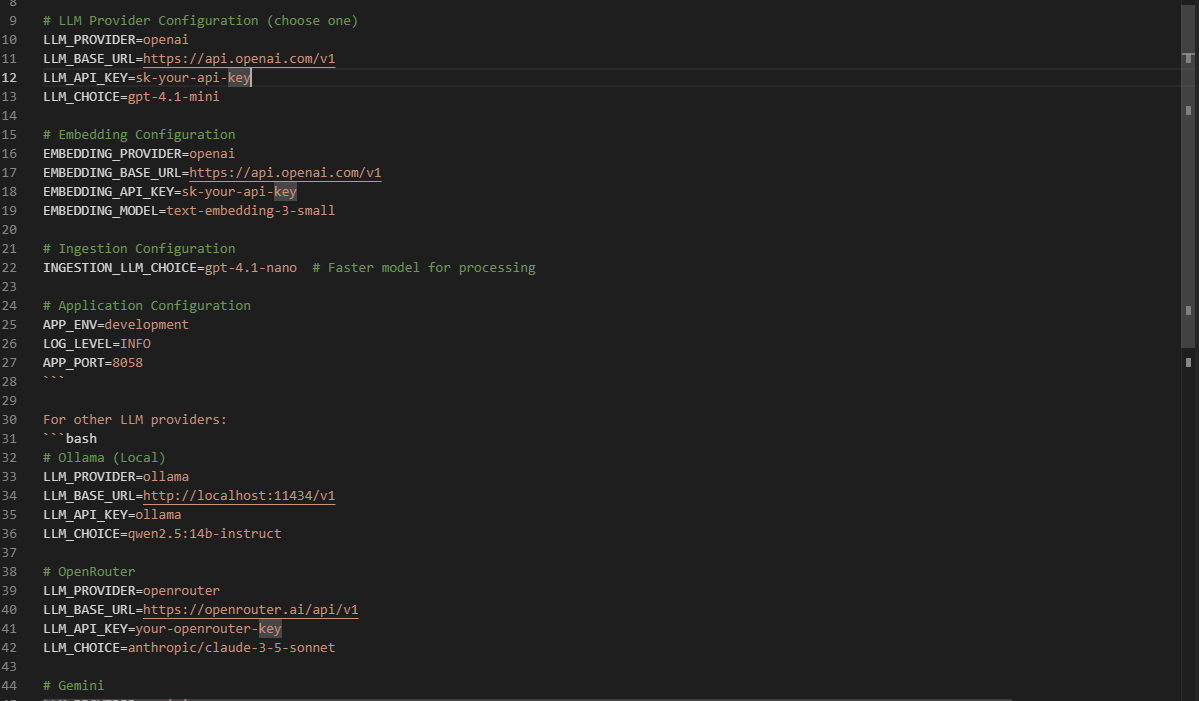
LLM_API_KEY=sk-your-api-key
LLM_CHOICE=gpt-4.1-mini
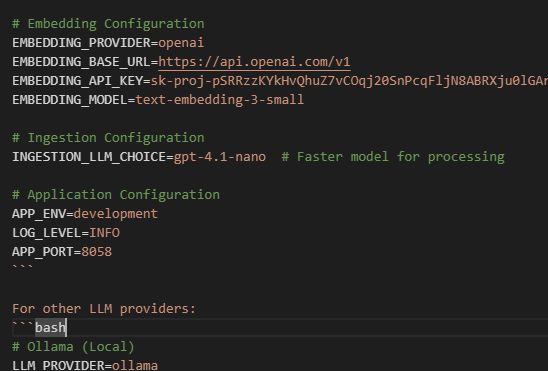
# Embedding Configuration
EMBEDDING_PROVIDER=openai
EMBEDDING_BASE_URL=https://api.openai.com/v1
EMBEDDING_API_KEY=sk-your-api-key
EMBEDDING_MODEL=text-embedding-3-small
# Ingestion Configuration
INGESTION_LLM_CHOICE=gpt-4.1-nano # Faster model for processing
# Application Configuration
APP_ENV=development
LOG_LEVEL=INFO
APP_PORT=8058
```
For other LLM providers:
```bash
# Ollama (Local)
LLM_PROVIDER=ollama
LLM_BASE_URL=http://localhost:11434/v1
LLM_API_KEY=ollama
LLM_CHOICE=qwen2.5:14b-instruct
# OpenRouter
LLM_PROVIDER=openrouter
LLM_BASE_URL=https://openrouter.ai/api/v1
LLM_API_KEY=your-openrouter-key
LLM_CHOICE=anthropic/claude-3-5-sonnet
# Gemini
LLM_PROVIDER=gemini
LLM_BASE_URL=https://generativelanguage.googleapis.com/v1beta
LLM_API_KEY=your-gemini-key
LLM_CHOICE=gemini-2.5-flash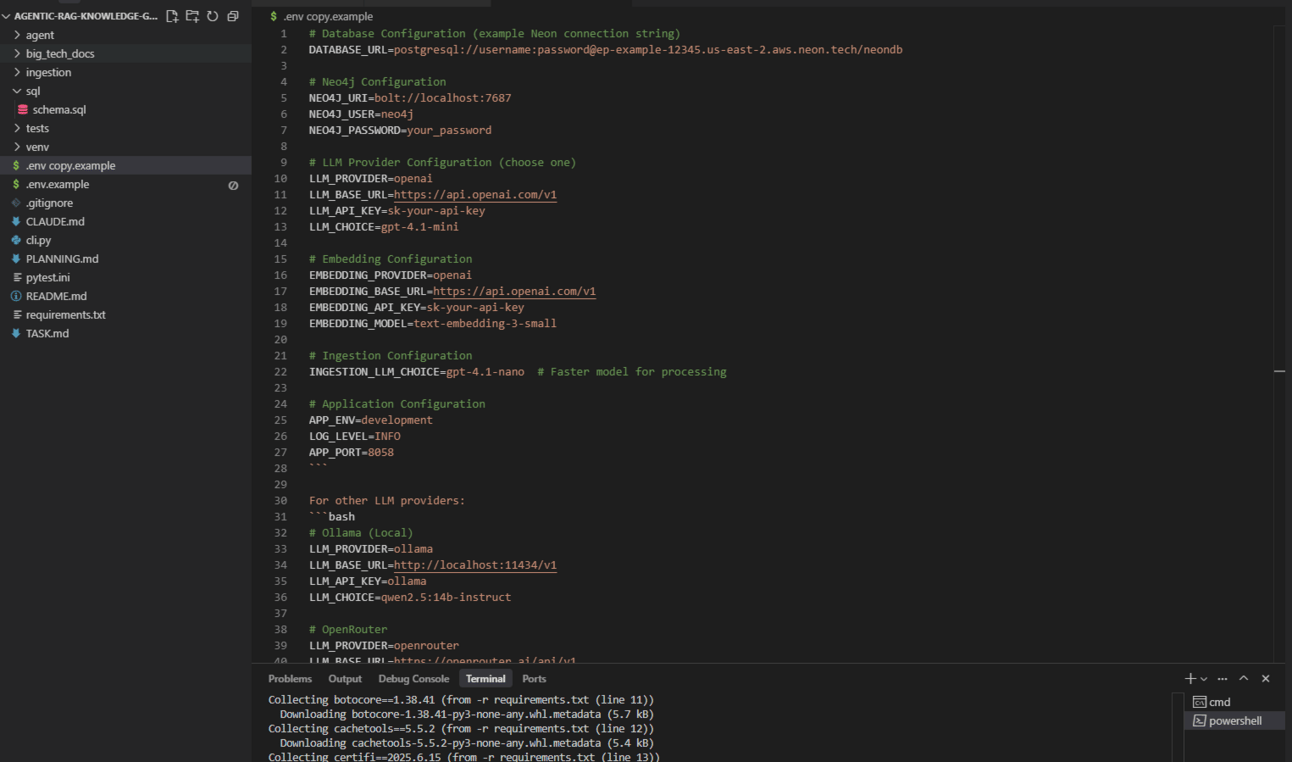
Let's walk through the necessary variables in your new .env file:
1. Database Connection. You'll need to set up the connection string for your PostgreSQL database. Find the DATABASE_URL variable and paste your connection details there. If you're using a hosted service like Neon, you can typically find this connection string directly in your project's dashboard.
Go to Neon Dashboard and click on Connect to the database. Here you’ll have the snippet.
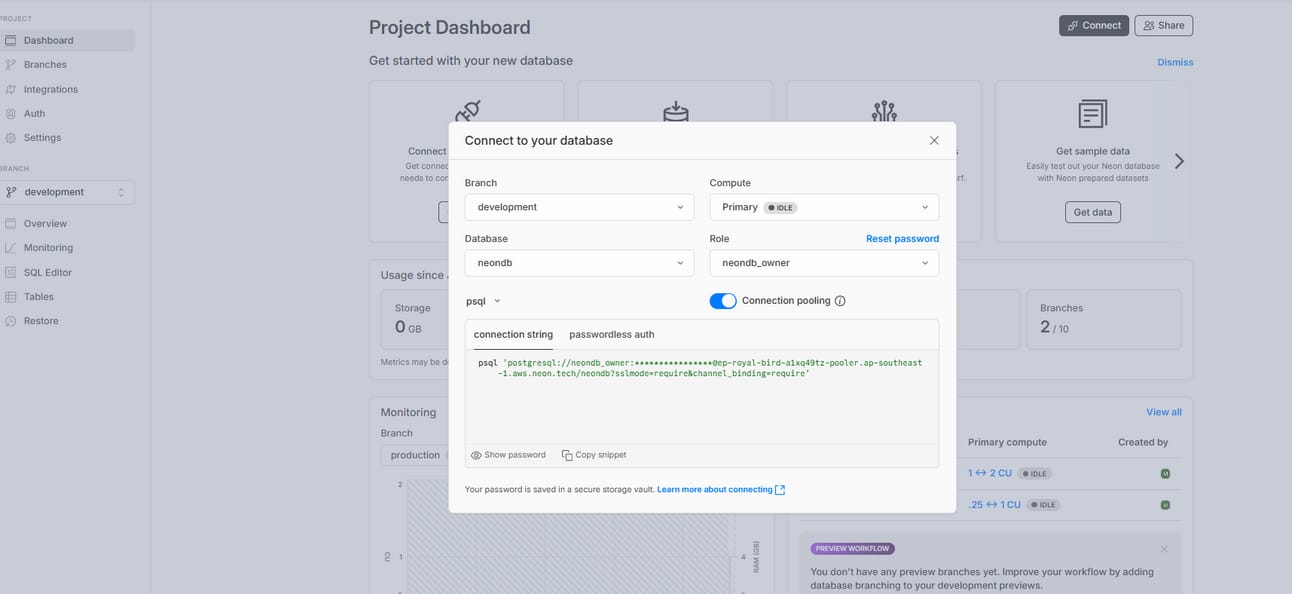
Copy and paste it into your DATABASE_URL.

2. Neo4j Graph Database. Next, configure the connection to your Neo4j instance. The default URL is usually fine (bolt://localhost:7687) but you must provide the NEO4J_USERNAME and NEO4J_PASSWORD that you created during the Neo4j setup process.
3. Large Language Model (LLM). This section tells the application which AI model to use for generating responses.
Provider: First, specify your
LLM_PROVIDER(e.g.,OpenAI,OpenRouter,Ollama,Gemini).Connection Details: Based on your provider, set the
LLM_BASE_URLand yourLLM_API_KEY.Model Selection: Finally, choose the specific
LLM_MODELyou want to use, such asgpt-4o-mini.
4. Embedding Model. Embeddings are used to represent your documents numerically. You'll need to configure the provider for this as well, which can be different from your main LLM provider. Set the EMBEDDING_PROVIDER, EMBEDDING_BASE_URL, EMBEDDING_API_KEY and EMBEDDING_MODEL accordingly.
Pro Tip: You can use different providers for your main language model and your embedding model. For example, you could use a local model via Ollama for the main reasoning tasks but use OpenAI's highly efficient model for creating the embeddings
5. Ingestion LLM (Optional) For processing and ingesting documents into your knowledge graph, you might want to use a separate, more lightweight LLM to save on costs and improve speed. You can configure this under the INGESTION_LLM variables. If you leave this blank, the application will default to using the main LLM you configured above.
The remaining variables in the file are for minor configurations and can usually be left as their default values.
Once you have filled in all these details and saved your .env file, your environment is fully configured. Now you're ready to move on to the next steps!
Step 5: Load Your Knowledge Base
Now it's time to feed your agent the information you want it to learn.
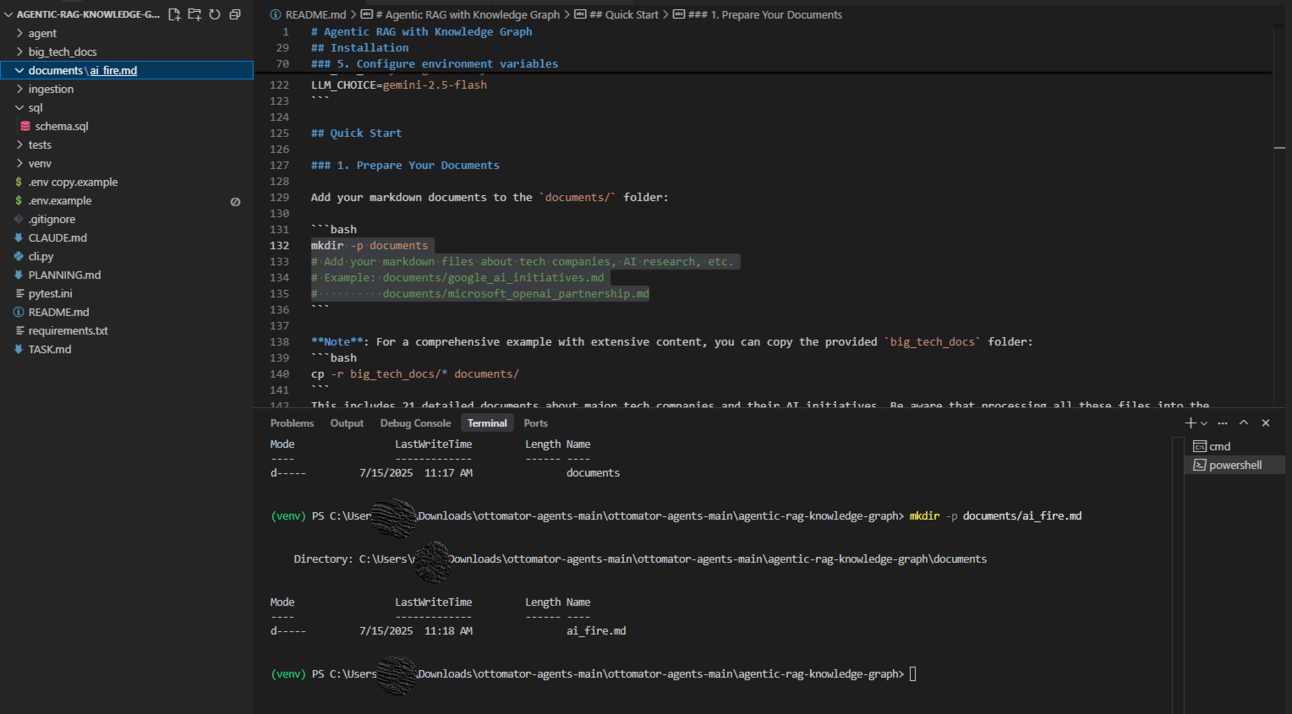
Action: In the project folder, create a new directory named documents/. Place any markdown files (.md) that you want to ingest into this folder. Here is the command to create it:
Action: To start the ingestion process, run the following command in your terminal:
python -m ingestion.test --clean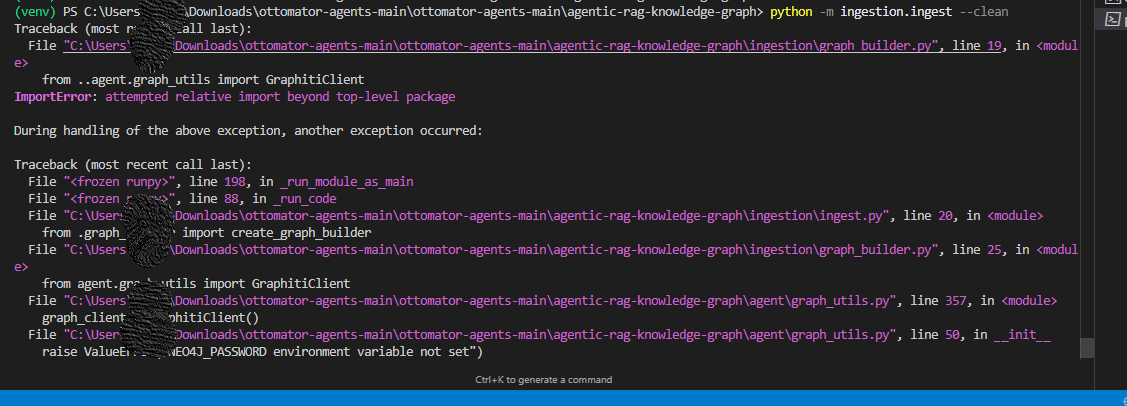
What's Happening? This script will:
Read all the markdown files in your
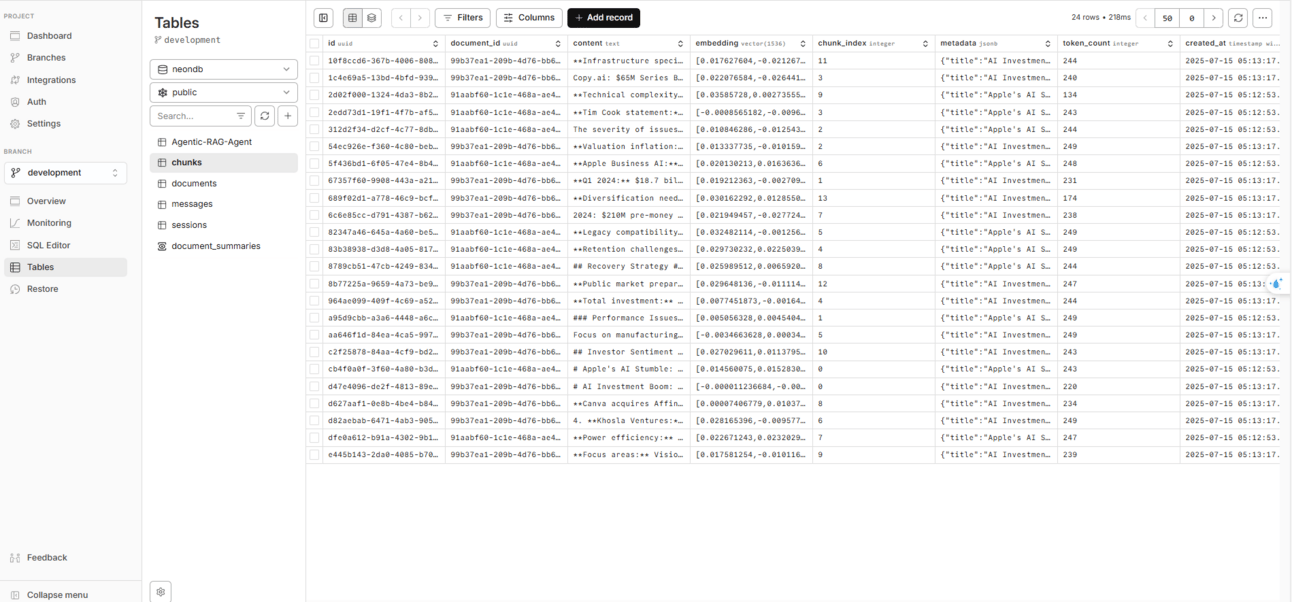
documents/folder.Split them into chunks, create vector embeddings for each chunk and store them in your PostgreSQL database.
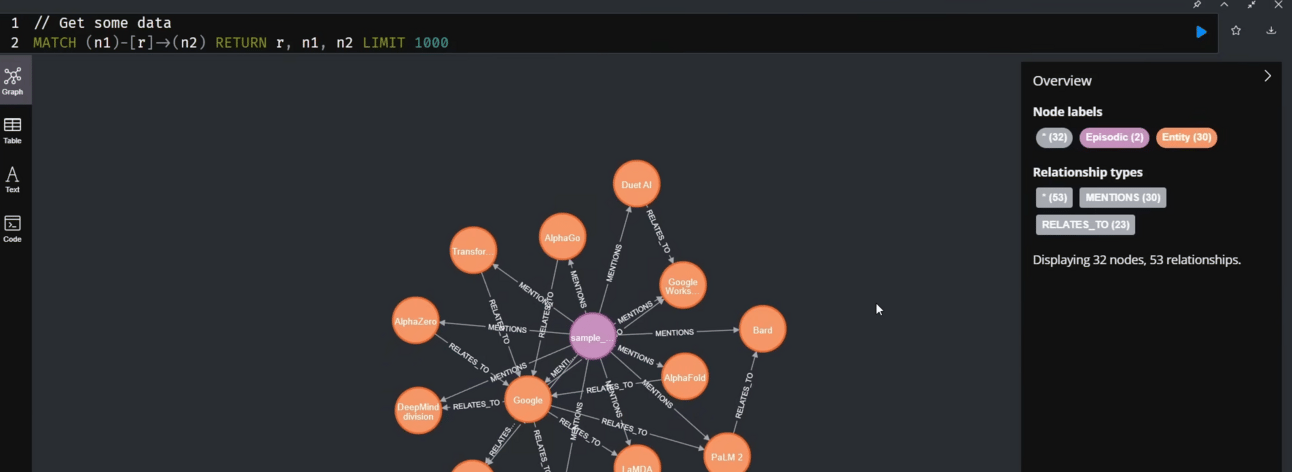
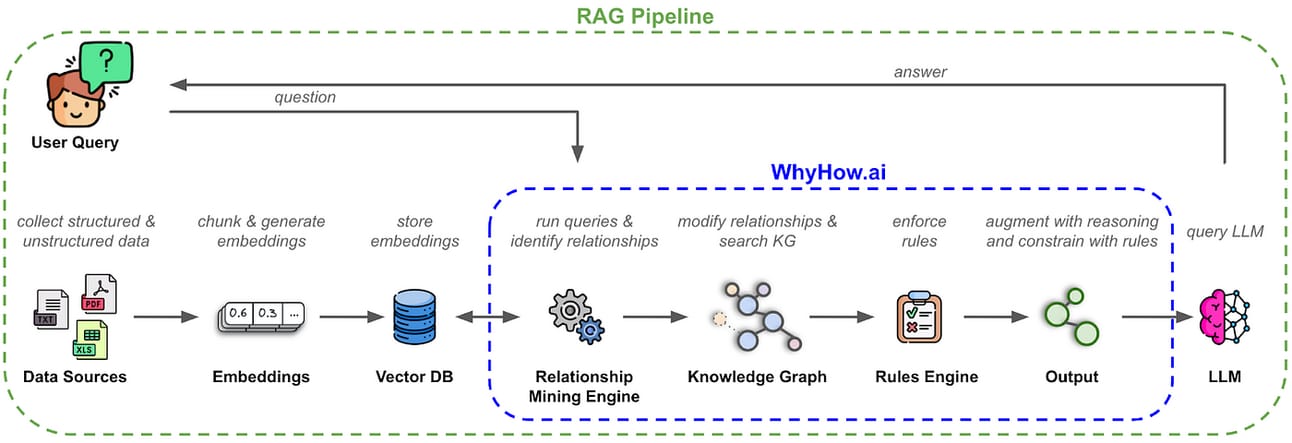
Use a language model to analyze the text, identify the key entities (like people, companies and products) and the relationships between them and then build out the knowledge graph in your Neo4j database.
Fair Warning: The knowledge graph creation process is computationally expensive because it uses an LLM to perform the entity and relationship extraction. Be patient, especially if you are loading a large number of documents. This is the step where the "understanding" is built and it's worth the wait.
Step 6: Launch Your Agent
Time for the magic moment.
Action 1: Start the API Server. In your terminal, run the following command:
python -m agent.api
Action 2: Start the CLI. Open a second, separate terminal window. Make sure you activate the virtual environment in this new window as well (
source venv/bin/activate). Then, run the following command:
python cli.py
And boom! You now have a fully functional, conversational AI research assistant with a deep understanding of your data, powered by both a vector database and a knowledge graph. You can start asking it questions.
Part 4: Testing Your New Agentic RAG Assistant
Now that your Agentic RAG system is up and running, it's time to put it through its paces and see the agentic reasoning in action. The beauty of this system is that you can watch in real-time which tools the agent chooses to use, giving you a window into its decision-making process.
Test 1: Simple Information Retrieval
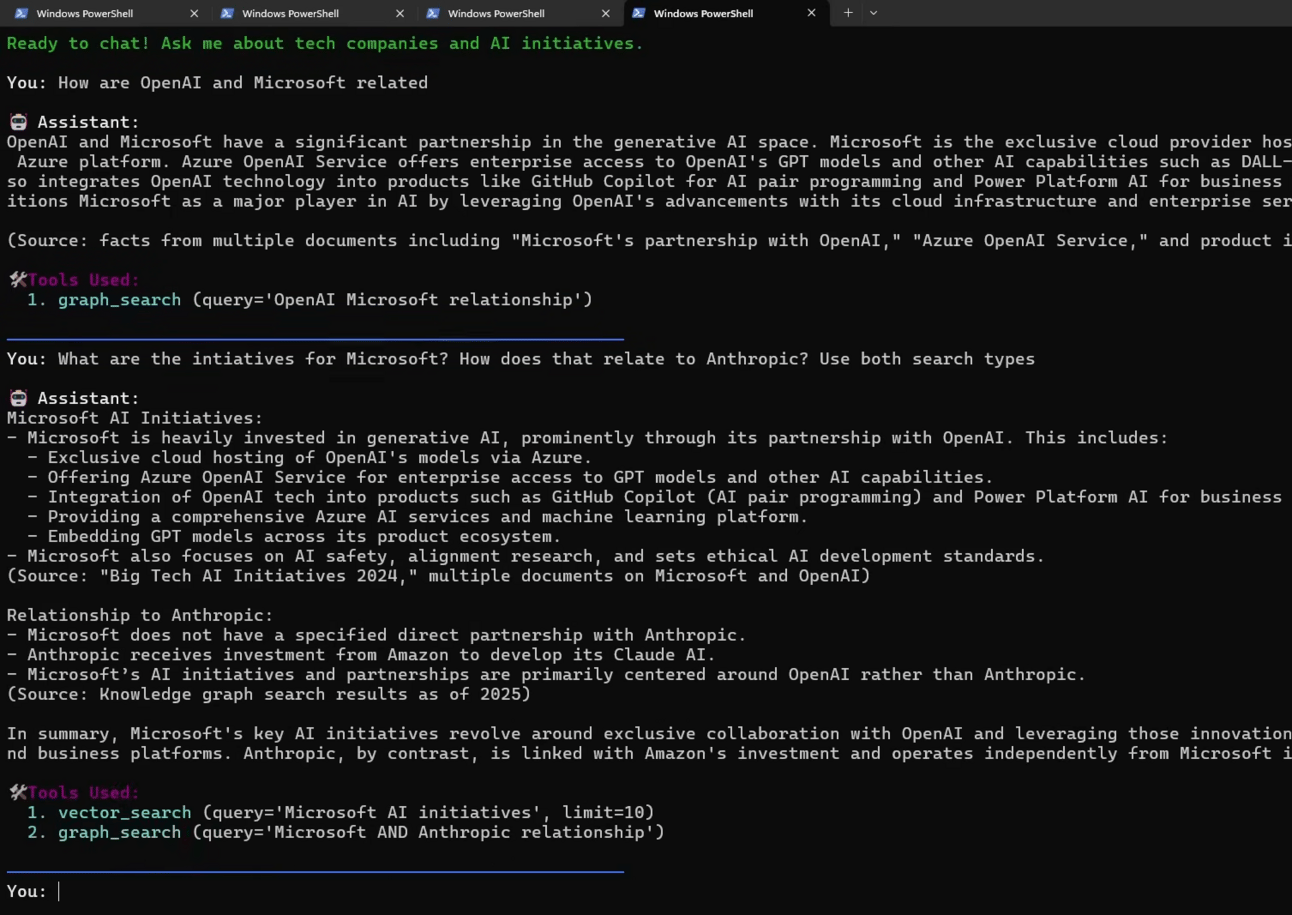
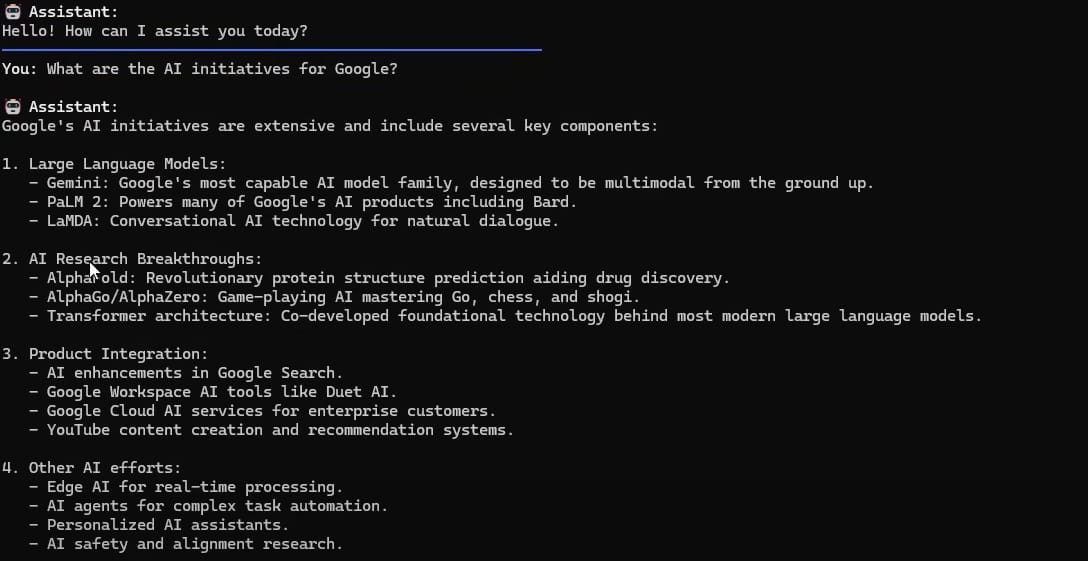
Your Prompt: "What are Google's AI initiatives?"
The Agent's Logic: The agent's internal prompt will analyze this question and determine that it is a request for factual information about a single entity ("Google"). It will conclude that a semantic search of the document chunks is the most direct and efficient way to answer.
Action: The agent will use the vector search tool to find all the chunks of text related to "Google AI initiatives".
Expected Result: You'll receive a comprehensive answer summarizing Google's projects, likely mentioning things like Gemini, their work on TPUs and their various AI research divisions, with sources cited from your documents.
Test 2: Relationship Analysis
Your Prompt: "How are Amazon and Anthropic connected?"
The Agent's Logic: The agent will recognize that this question is not about Amazon or Anthropic individually but about the connection or relationship between them. Its internal rules will tell it that relationship queries are best answered by the knowledge graph.
Action: The agent will use the graph search tool. It will query the Neo4j database for the "Amazon" and "Anthropic" nodes and find the path that connects them.
Expected Result: The agent will explain their multi-billion dollar investment relationship and Amazon's role as a key infrastructure provider for Anthropic through AWS, a detail it would be difficult to piece together from scattered document chunks alone.

Test 3: Complex Multi-Step Reasoning
Your Prompt: "Compare Microsoft's AI strategy with OpenAI's approach".
The Agent's Logic: The agent will identify this as a multi-step task. First, it needs to understand Microsoft's strategy. Then, it needs to understand OpenAI's strategy. Finally, it needs to analyze the relationship between them to provide a comparison.
Action: The agent will first use vector search to gather the individual details about each company's strategy. Then, it will use graph search to find their partnership relationship in the knowledge graph.
Expected Result: You’ll get a detailed analysis that combines individual facts with relational context, providing a much deeper and more nuanced answer than a simple search could ever provide.

Creating quality AI content takes serious research time ☕️ Your coffee fund helps me read whitepapers, test new tools and interview experts so you get the real story. Skip the fluff - get insights that help you understand what's actually happening in AI. Support quality over quantity here!
Part 5: Advanced Customization (For the Ambitious)
Once you have the basics working, you can start to modify and extend the system to fit your specific needs. This is where the power of having an open-source framework really shines.
Custom Entity Types: The default setup is trained to recognize common entities like "Person", "Organization", and "Product". However, you can modify the extraction prompts to recognize industry-specific entities. For example, if you are building a system for healthcare research, you could train it to identify and link entities like "Disease", "Treatment", "Medication", and "Clinical Trial".
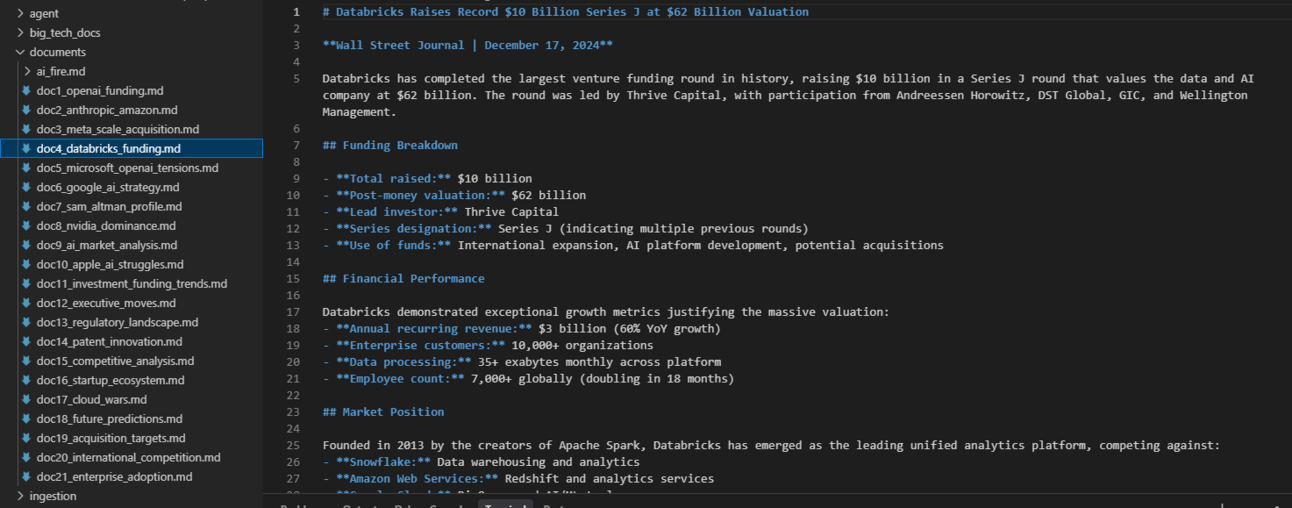
Multi-Modal Knowledge: The vector database is not limited to text. You can extend the system to handle images, audio clips and even video by using multi-modal embedding models. This would allow you to build a knowledge base where you could ask questions like, "Show me all the images related to our Q3 product launch".
Real-Time Updates: You can set up an automated pipeline (for example, using a tool like n8n) that watches for new documents being added to a specific folder. When a new document appears, it can automatically trigger the ingestion script to process the new information and update both the vector database and the knowledge graph in real-time.
Performance Optimization: For very large knowledge bases, you can implement caching for frequently accessed graph paths and common vector searches to improve response times.

Part 6: The Claude Code Magic (How This Was Built in 35 Minutes)
Here's the insider secret: I used an advanced AI-assisted development technique, often called Context Engineering, with a tool like Claude to build about 90% of this system. This wasn't because I'm lazy but because it's an incredibly powerful and efficient way to work.
My Process:
Planning Phase: I started by creating a detailed project specification in a markdown file. This described the high-level architecture, the different components (database, knowledge graph, API) and the desired functionality.
Context Setup: I configured my AI assistant with access to the official documentation for Pydantic AI, FastAPI, Neon and Neo4j using MCP servers.
Agentic Building: I then gave the AI a high-level prompt: "Based on my project plan, please build this entire application". I then let the AI run for about 35 minutes. It read the plan, consulted the documentation and wrote everything from the database schemas and API endpoints to the ingestion scripts and the CLI.
Iterative Refinement: I guided the process by providing examples from my previous projects to influence the coding style and structure.
Why This Worked So Well: Instead of getting bogged down in the tedious work of writing every single line of code, I was able to focus on the high-level architecture and strategy. I acted as the film director and the AI became my incredibly skilled camera operator, lighting technician and editor.
Part 7: Common Gotchas and How to Avoid Them
As with any complex system, you might run into a few common issues.
Problem 1: The knowledge graph creation is taking forever.
Solution: During development and testing, you can use the
--no-knowledge-graphflag when running the ingestion script. This will skip the most computationally expensive step and allow you to quickly test the vector search functionality.
Problem 2: The agent always uses the same search method, even when it shouldn't.
Solution: You need to refine the system prompt that guides the agent's decision-making process. Make the criteria for choosing between vector search and graph search clearer and more explicit.
Problem 3: The vector search is returning irrelevant results.
Solution: Experiment with different embedding models and, more importantly, different chunking strategies. Instead of just splitting your documents into fixed-size chunks, try using a semantic chunking method that splits the text based on logical breaks in the content.
Problem 4: You're having issues connecting to your Neo4j database.
Solution: Double-check your Neo4j credentials in your
.envfile. Also, make sure that the Neo4j service is actually running on your computer. The Neo4j Desktop application provides an easy way to start, stop and debug your local graph database.
Conclusion: The Future of AI is Not Just Search, It's Understanding
Traditional RAG is like having a really good search engine. It will find you relevant information but it can't connect the dots or reason about the relationships within that information.
Agentic RAG with Knowledge Graphs is like having a brilliant research assistant who not only knows where to find every piece of information but also understands how everything connects to everything else.
The system we have just built represents months of research, experimentation and refinement. It is a production-ready template that gives you a massive head start in building the next generation of AI applications. But this is about more than just the code. It's about understanding a fundamental shift in how we should approach AI-powered information retrieval. We are moving from simple search to intelligent reasoning and from static databases to dynamic, interconnected knowledge networks.
Your homework is to set this system up, load it with your own documents - your company's internal documentation, your personal research notes or any domain-specific knowledge you have - and start experimenting. Ask it different types of questions. See how the agent reasons about your specific domain. Push the boundaries of what's possible.
The future of AI isn't just about bigger and better models. It's about building better systems that can reason, adapt and truly understand the complex web of relationships in your data. And with this guide, you are now equipped to build that future for yourself.
If you are interested in other topics and how AI is transforming different aspects of our lives or even in making money using AI with more detailed, step-by-step guidance, you can find our other articles here:
Overall, how would you rate the AI Workflows Series? |
Reply