- AI Fire
- Posts
- 🚨 META BREAKS THE LIMITS

In partnership with

Meta went nuclear with gigawatt-scale contracts, OpenAI went clinical with a full medical model stack tuned by hundreds of physicians, and Google pushed Gemini everywhere from your inbox to your living-room TV.
What's on FIRE 🔥
IN PARTNERSHIP WITH THE WEEKEND CLUB

The Weekend Club uses AI to match 6 people for a 2-hour brunch. 2,000+ paid attendees/month in aross Asia. Franchise it - HQ provides app+payments+SOPs; you book venues, grow community, earn per seat.
AI INSIGHTS
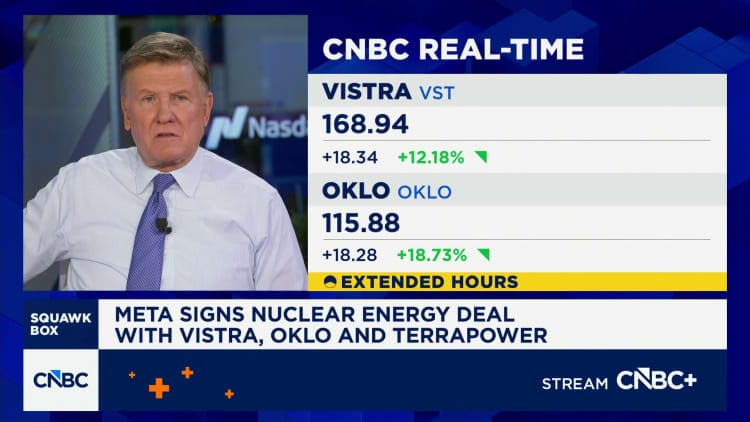
Source: CNBC
Meta just made one of the boldest energy bets in big tech history, locking in over 6 GW of nuclear power to fuel its expanding data center empire.
And not just with legacy providers. Meta’s going nuclear with a mix of old reactors and tiny, next-gen modular ones (SMRs). Who’s in the deal?
Vistra (Legacy player): 2.1 GW from existing Ohio plants + 433 MW in upgrades
Oklo (SMR startup): 1.2 GW deal using 75 MW Aurora Powerhouse units
TerraPower (Bill Gates–backed SMR startup): 690 MW in first phase, with options to scale to 2.8 GW + 1.2 GW storage
These deals came from a Meta RFP in late 2024 asking for 1–4 GW of new generating capacity by the early 2030s. And now, they’ve got it locked in.
Meta’s AI ambitions mean 24/7 stable baseload energy, and nuclear is basically the only clean source that fits the bill. But there’s not enough of it. That’s why they’re turning to SMRs.
And all of this feeds into the PJM grid - a key U.S. interconnect already maxed out with AI data center demand. Just like Apple makes its own chips, and OpenAI is building custom silicon with Microsoft, Meta also kicks SMRs into the real world.
PRESENTED BY THE MARKETING MILLENNIALS

The best marketing ideas come from marketers who live it.
That’s what this newsletter delivers.
The Marketing Millennials is a look inside what’s working right now for other marketers. No theory. No fluff. Just real insights and ideas you can actually use—from marketers who’ve been there, done that, and are sharing the playbook.
Every newsletter is written by Daniel Murray, a marketer obsessed with what goes into great marketing. Expect fresh takes, hot topics, and the kind of stuff you’ll want to steal for your next campaign.
Because marketing shouldn’t feel like guesswork. And you shouldn’t have to dig for the good stuff.
AI SOURCES FROM AI FIRE
1. The new way to build profitable AI websites with Gemini 3. Most websites fail in seconds. Simple steps for beginners with zero tech skills.
2. How to attract high-value clients in 2026 with just one clear positioning move. How to stop selling on price and start attracting clients who value results
3. Easy guide to make a realistic talking AI Clone that looks just like you (same tone, voice,...). Build your AI avatar that speaks 40+ languages and auto scales content
FIRE RECAP: BIGGEST AI NEWS THIS WEEK
🩺 OpenAI just launched ChatGPT Health plus an enterprise suite for hospitals, powered by GPT-5.2 and tuned with 260+ physicians. Already live at top US hospitals. Full rollout inside ChatGPT-Health.
⚡ OpenAI and SoftBank each put $500M into a clean-energy plan that builds a 1.2-gigawatt data center in Texas for future AI workloads. More details on SB-Energy.
📬 Gmail entered the Gemini era with AI Inbox, AI Overviews for threads, and stronger Help Me Write + Proofread. Gmail finally feels smart with Gemini-3.
📺 Gemini is now on TVs: Nano Banana and Veo run directly on Google TV for AI video clips, photo edits, and slideshows. Plus visual cards and voice-controlled settings via Google-TV-AI.
💰 Anthropic is discussing a $10B raise at a $350B valuation, nearly doubling in months as Claude demand spikes. Full funding story in Anthropic.
TODAY IN AI
AI HIGHLIGHTS
💸 Elon Musk’s xAI burned nearly $8B in 9 months while racing to build AI agents that will power Optimus. Revenue doubled QoQ, but losses jumped past $1.4B. Full breakdown inside xAI.
🛡️ Perplexity just launched a secure multimodal AI stack for law enforcement - scene photos, bodycam transcripts, policy Q&A, all with enterprise-grade privacy. Agencies get 12-months-free.
📈 Z.ai became the first AGI company listed on the Hong Kong Stock Exchange (HKEX: 02513). They’re celebrating with a 48-hour community challenge packed with credits and rewards via GLM.
🏥 OpenAI released a regulated GPT-5.2 stack for hospitals, tested on real clinical tasks with evidence citations, policy integration, and medical templates.
🤖 China dominated 2025 humanoid robot shipments, with AgiBot and Unitree scaling “physical AI” production and taking over CES. Full global breakdown of AI-robots.
💰 AI Daily Fundraising: LMArena has raised $150M in Series A funding led by Felicis and UC Investments, with major backers like Andreessen Horowitz, Kleiner Perkins, and Lightspeed. Demand is surging as top AI labs use the platform as the gold-standard for real-world AI evaluation and benchmarking.
NEW EMPOWERED AI TOOLS
🧠 Repo Prompt analyzes your project and selects the files and functions needed for your task
🗂️ Promptsy is your personal prompt vault. You can save, organize, version, and share AI prompts there
📊 Livedocs uses AI to generate charts, metrics, and clear answers, no setup. Built for anyone who needs insights fast
💱 xPay is a powerful cross-border payment solution for enterprises with 90% success rates, multi-currency support
AI BREAKTHROUGH
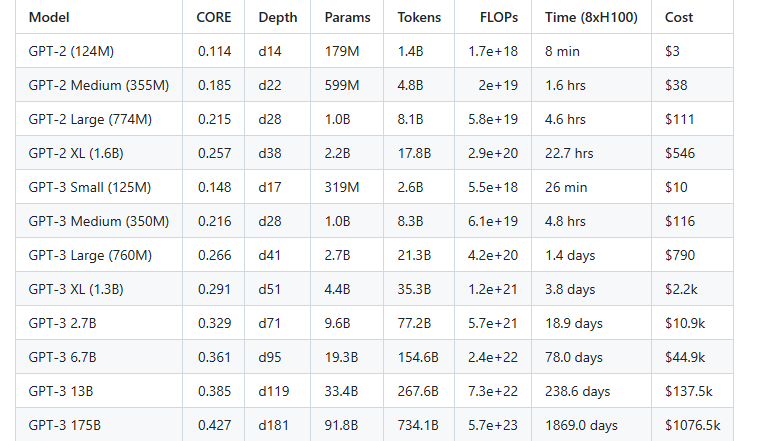
Andrej Karpathy just dropped one of the clearest, most useful blog posts on LLM training we’ve seen in a while, and he didn’t need 1,000 GPUs or a billion-dollar lab to do it.
Instead, he asked a painfully simple question: “If you only have a fixed compute budget, what’s the best way to spend it when training a small language model?”
To answer that, he trained 11 models of different sizes using:
The same dataset
The same batch size
The same compute limit
He then used a single evaluation score (averaged over 22 tasks), a real-world cost estimate: $24/hour for 8×H100s. Now anyone can look at the results and say, “Ah, that’s what $5K gets you.”
There’s a sweet spot for model size on any fixed compute budget:
Training Tokens ≈ 8 × Number of Parameters
And it works shockingly well. Just keep that 1:8 ratio. And you’ll get near-optimal performance for your budget. You can avoid wasting money on models too big to converge or too small to matter.
We read your emails, comments, and poll replies daily
How would you rate today’s newsletter?Your feedback helps us create the best newsletter possible |
Hit reply and say Hello – we'd love to hear from you!
Like what you're reading? Forward it to friends, and they can sign up here.
Cheers,
The AI Fire Team
Reply