- AI Fire
- Posts
- 💰 The AI Revolution Isn't A Bubble. It's An "Infinite Money Glitch"
💰 The AI Revolution Isn't A Bubble. It's An "Infinite Money Glitch"
AI isn't a bubble, open-source is winning, and compute is the real bottleneck. Here are the 12 lessons learned from 2 years in the AI trenches
Max Anh
October 28, 2025

🤔 In the Great AI Gold Rush, Who Holds the Real Power?This article is a deep 28-month analysis of the AI industry. As this revolution unfolds, where do you think the true, lasting advantage lies? |
|
Table of Contents
Introduction: Skin in the Game
Over the last 28 months, the world has been obsessively focused on one thing: artificial intelligence. But this isn't a casual observation or a weekend hobby. This analysis comes from a perspective of "skin in the game" - a career, reputation and life's work bet entirely on the power of the AI revolution to change everything.

This is not armchair analysis; it’s pattern recognition from direct experience, backed by building AI products, running an AI agency and watching the industry evolve in detail every day.
While many are still debating, a huge shift has already occurred. This complete guide will break down the major trends, share critical insights most people are missing and make specific, actionable predictions for 2026 and beyond. Get ready to explore:
Why AI is definitely not a bubble (and where the real bubble is).
The breakthrough technology that's quietly driving progress.
The unique data advantages that will determine the winners.
The real-world job displacement that's already begun.
The market consolidation that will kill most AI startups.
Why learning to code is about to become "sexy" again.

Part 1: Is AI a Bubble? The Definitive Analysis
The hottest and most debated topic in tech right now is whether the AI revolution is a massive financial bubble, similar to the 2001 dot-com crash or the 2021 crypto mania.
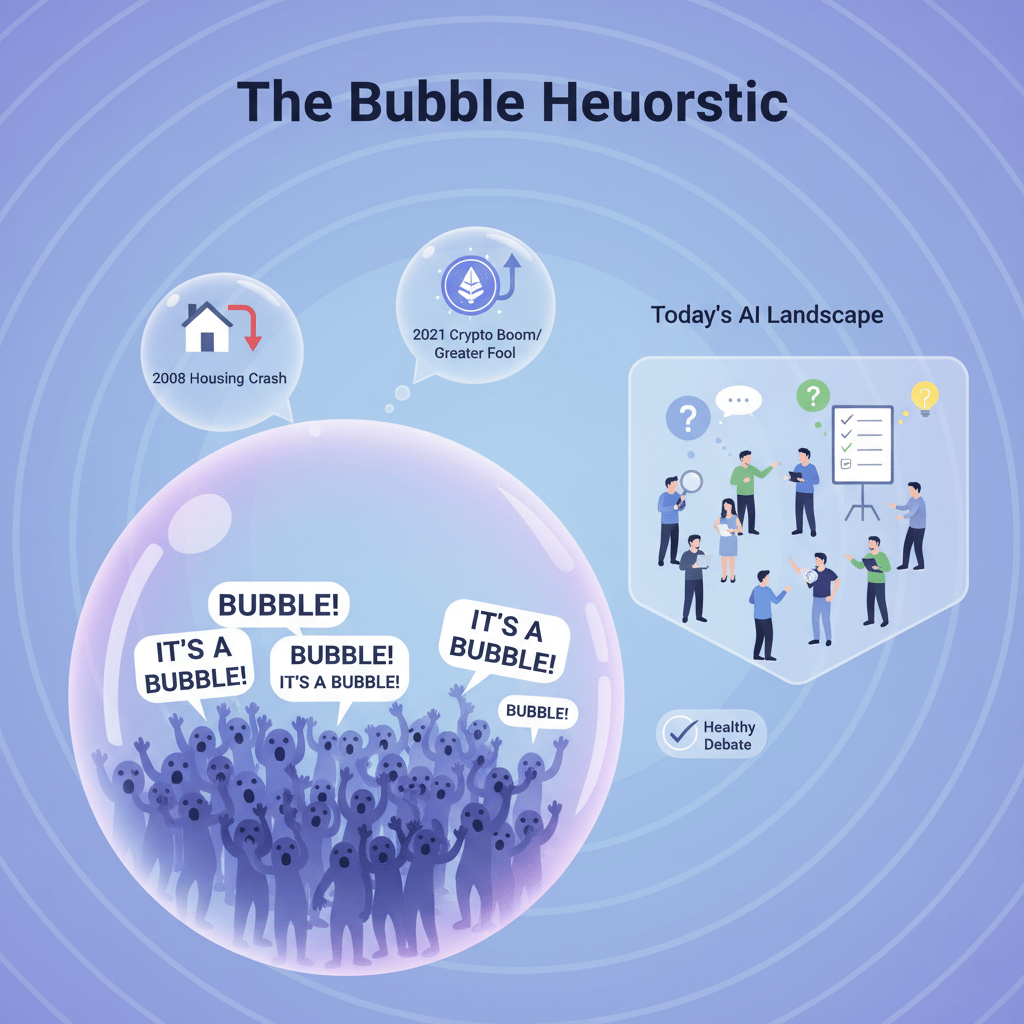
The Bubble Heuristic
A useful rule helps here: if everyone is screaming that it’s a bubble, it’s probably not a bubble. A true bubble requires a collective, unquestioning belief that returns will continue forever.
In the 2008 financial crash, investors genuinely believed housing prices could never fall.
In 2021, crypto investors championed the "greater fool theory", convinced they could sell their assets to someone else for more.
Today's AI landscape is full of doubt and debate, a healthy sign that a widespread craze hasn’t taken hold.
Arguments for the Bubble Theory
To be fair, the "bubble" supporters have some strong evidence.
Insane Investment Levels: The money flowing into AI is unlike anything before. Big Tech (Google, NVIDIA, OpenAI, Meta) is investing hundreds of millions per hire for top talent. Seed rounds, which are typically for early-stage ideas, are raising $17 million. Pre-product companies, like those from former OpenAI researcher Ilya Sutskever or Andrej Karpathy, are raising billions before launching a single product.

Unproven Business Models: Many AI startups currently have no revenue, zero product-market fit and completely unproven track records, yet they are burning through millions of dollars per month in compute costs and salaries. This certainly looks like a bubble.

Why This Isn't 2021 Crypto or 2001 Dot-Com
The comparison to past bubbles fails when you examine two critical, basic differences.
Critical Difference #1: Real, Practical Use Cases
The AI revolution is not built on speculation; it's built on utility.
The Crypto Comparison: The 2021 crypto bubble was driven by pure speculation. Most cryptocurrencies have no real-world use case. NFTs, the peak of this craze, were digital assets with value coming only from the belief that someone else would pay more for them later.

The AI Reality: AI is already clearly useful. You are likely using it daily. Businesses are using it daily. It provides immediate, practical value, from writing code and drafting emails to analyzing data and generating media. This isn’t theoretical future value; it’s real, present-day utility.

Critical Difference #2: Actual, Explosive Revenue Growth
Unlike the dot-com companies that just added ".com" to their names to triple their valuations without revenue or crypto companies with zero income, the leaders in the AI space are experiencing real and historic revenue growth.
Anthropic (Claude): Reported 10x revenue growth year-over-year. Not 100% growth but 1,000%.
OpenAI (ChatGPT): Has shown unprecedented revenue acceleration from near zero to billions.
NVIDIA: The company building the "shovels" for this gold rush is reporting earnings that consistently beat analyst expectations.
Industry Context: A healthy company in the S&P 500 might see ~12% annual growth. A high-growth tech startup shooting for 100% YoY growth is considered exceptional. A 10x (1,000%) growth rate is historically unmatched at this scale.

The Verdict: Not a Technology Bubble
Could there be a pullback? Absolutely. A 10-30% correction in AI-related stocks is likely in the short term. But that’s just normal market ups and downs, not a systemic crash.
The VC and startup market, however, is a different story. Many overfunded startups with no revenue and no protective moat will burn through their capital and fail. This is a VC bubble but it's not a technology bubble.
The 2001 dot-com crash saw the NASDAQ decline by 80. That isn't going to happen to AI, because the technology is fundamentally transformative, the revenue is real and the use cases are expanding daily.
Betting against AI's core value is betting against the next wave of human productivity. It's a bet that few with serious skin in the game are willing to make.

NASDAQ Composite Index for the period 1998 to 2001
Learn How to Make AI Work For You!
Transform your AI skills with the AI Fire Academy Premium Plan - FREE for 14 days! Gain instant access to 500+ AI workflows, advanced tutorials, exclusive case studies and unbeatable discounts. No risks, cancel anytime.
Part 2: The Reinforcement Learning Breakthrough
Many users and analysts felt that GPT-5 was "disappointing" upon its release. But they missed the point. GPT-5 was intentionally smaller than its predecessor, GPT-4.5.
OpenAI made it more compute-efficient to serve more users, offer faster responses and make it accessible on free tiers.

The real frontier isn't just building bigger and bigger models. The breakthrough that is keeping the momentum of the AI revolution going is Reinforcement Learning (RL) combined with "test-time compute".
Why Reinforcement Learning Changes Everything
Without RL, the AI industry would likely be stuck and we might be in a stock market crash. The "transformer" architecture, while brilliant, is showing signs of saturation. We have scraped and saturated the entire text of the public internet.
Reinforcement Learning provides a new path forward. It's a method of training where an AI agent learns by doing a task and receiving rewards or penalties for its actions.
The Saturation Principle: As long as you can create a benchmark (a test) for evaluating performance on a specific task, an RL agent can eventually "saturate" or master that benchmark.
Hot Investment Opportunity: This is why startups building specialized RL training environments are booming in San Francisco. These are digital sandboxes where AI agents can be trained on specific tasks, like navigating an e-commerce site. An agent can be trained to browse products, add items to a cart and check out, learning the specific actions required.

The Deterministic Advantage: Code and Math
Models need to be trained on actions, not just passive text. This is why we are seeing massive, huge gains in AI's coding and math abilities, while creative tasks are improving more slowly.
Coding and Math are Deterministic: These domains have clear right and wrong answers.
Math: If an equation doesn't work or a theorem is flawed (e.g., it results in 1=2), the AI can immediately discard that reasoning path.
Code: If a program doesn't compile, throws errors or doesn't run, it's rejected.

The Synthetic Data Advantage: Because success is so easy to validate, AI can generate massive amounts of synthetic training data for itself. It can try to solve a coding problem 500 different ways. Even if only 1 of those 500 attempts works, the AI can isolate that one successful "reasoning trace" and train itself on it.

Creative Tasks are Subjective: Image generation, copywriting and video editing involve taste. There is no clear right or wrong answer, making it much harder to create a benchmark for an RL agent to train against.
The path forward for AI capabilities is clear: build more RL environments for specific, deterministic action sets. This creates new training data that goes far beyond the static text of the internet.
Part 3: The X AI Prediction (Validated)
A year ago, most analysts said Elon Musk's X AI was too far behind and would never catch up to the leaders. This analysis proved wrong. The reason X AI was always going to catch up lies in a simple, basic concept: unique, company-owned data.
Musk has four key advantages that competitors lack:
Manufacturing & Infrastructure Mastery: He is arguably the best in the world at solving large-scale, real-world engineering and manufacturing bottlenecks.
Capital: As one of the world's richest people, he can afford the massive spending (capex) to buy the necessary GPUs.
Talent Attraction: Top-tier AI researchers want to work with him and be part of history.
Unique Data Advantages: This is the most important one.

X (Twitter) Data: The World's Real-Time Conversation
Musk's purchase of Twitter was partially for free speech but significantly for data access. X AI has exclusive, legal access to the real-time, global stream of human conversation.
Competitors like OpenAI, Anthropic and Google are legally prohibited from scraping this data. This gives Grok, X's AI, a unique understanding of current events, slang and public opinion.

Tesla Data: The World's Physical Feedback Loop
Tesla's fleet of vehicles provides a massive, continuous stream of real-world video footage. This is invaluable for training Full Self-Driving (FSD) but its value extends far beyond that. This data can be used to train powerful video models and "world models" that understand physical interaction.

Optimus Robot Data: The Unscraped Trillion-Dollar Moat
This is the ultimate data advantage. In the future, the Optimus humanoid robots will generate a new class of data: three-dimensional, physical, embodied data.
The Human Advantage: A 10-year-old human can perform a simple hand gesture or pick up a glass, tasks that are impossibly complex for most robots. Why? Because humans learn from physical feedback, not just text.
The Token Gap: A human child has far fewer “tokens” of input (words, sights, sounds) than the trillions fed to GPT-5, yet is far more intelligent and general-purpose. This is because humans have access to unscraped data.

The Unscraped Data Problem: AI's Common Sense Gap
What's missing from all AI training? The data that isn't on the internet.
In-person social dynamics: An AI doesn't know how to act in a hallway meeting with a CEO because it has never experienced real-world hierarchy or social cues.
Physical feelings and feedback: An AI doesn't know why it's bad to eat processed carbs because it can't "feel" the sluggishness afterward. It has no consequences for its actions.
Embodied experience: Humans learn from biological evolution (50,000 years of tribal dynamics) and childhood (playground interactions). AI has access to none of this.
The Optimus robots will be the first AI to generate this priceless physical world data at scale. This "embodied" data - understanding physics, manipulation and real-world consequences - is a token stream that competitors cannot access. This is a moat that could be worth trillions.

Part 4: The Death of AI Doomerism
One of the biggest and healthiest trends of 2025 has been the disappearance of "AI Doomerism".
Remember 2023 and early 2024? The conversation was dominated by fear about humanity's future:
The "paperclip problem" (an AI optimizing for a goal with disastrous side effects).
AI "escaping containment" from its server.
"Hard takeoff" scenarios where a superintelligence emerges overnight.
Constant existential risk debates.

By Q4 2025, no one talks about this anymore. Why? Because the more people actually use AI, the more they intuitively understand what LLMs are.
The 2025 Reality: They Are Just Tools
People now understand that LLMs are:
Large language models.
Next-token predictors.
Not sentient beings plotting world domination.
Not going to "eat you alive", "turn you into paperclips" or "achieve consciousness" (at least with their current architecture).
That entire story has been put back into science fiction where it belongs.

The 30-50 Year Warning
Could a "rogue AI" become a real threat in 30-50 years, especially when advanced AI architectures are integrated with swarms of drones and humanoid robots? Possibly. It's a valid long-term discussion.
But in the Q4 2025 reality, the evidence is overwhelming: AI doomerism, as a near-term threat, was largely an unfounded fear. The focus has rightly shifted from panic about humanity's future to solving the real-world problems of today, like bias, labor disruption and market consolidation.

Part 5: Open Source is Catching Up (And Overtaking)
A quiet, underreported part of the AI revolution is happening: open-source models are now matching and, in some cases, exceeding the performance of closed-source models.
The GLM 4.6 Game-Changer
A prime example is GLM 4.6, a super-powerful open-source coding model.
Performance: On many popular benchmarks, it performs better than Anthropic's Claude Sonnet and even the new Sonnet 4.5.
The Question: Why isn't everyone talking about this? Why isn't it front-page news?

Why Open Source Isn't Getting Credit
There are two main reasons this revolution is happening just beneath the surface.
Incumbent Incentives: The big AI labs (OpenAI, Anthropic, Google DeepMind) have every financial incentive to bury or ignore the success of open-source models. They want to protect their “moats,” so they push “China is scary” stories or simply ignore competing models in public.
The Inference Infrastructure Problem: This is the more practical barrier. Most cloud inference infrastructure (the GPUs and TPUs you rent) is heavily optimized to run the most popular, profitable models: the GPT and Claude series. When new, powerful open-source models (like DeepSeek, Qwen or GLM) appear, the cloud compute isn't yet optimized for their specific architectures. This makes them seem slower or less efficient, even if the model itself is superior.

The Shocking Example
Consider the market valuations:
Anthropic: Worth ~$200 billion, with ~$35 billion in investment.
Zhipu AI (GLM): A Chinese lab most people hadn't heard of until 3 months ago. Yet, the open-source model from Zhipu AI is now comparable to Anthropic's most powerful offerings. This is an incredible validation of the power and speed of the open-source community.

Part 6: The Rise of Smaller, Faster Models
The era of "bigger is always better" for AI models is ending. The new focus of the AI revolution is on efficiency and speed, leading to the rise of smaller, specialized models that are often more useful than their giant versions.
Claude Haiku 4.5: More Useful Than Sonnet?
Anthropic recently released Haiku 4.5. Here's a controversial take: for many real-world applications, Haiku might be more useful than the more powerful Sonnet model.
Why?
It's Three Times Cheaper: This dramatically lower cost makes AI applications that were previously economically impossible, suddenly possible. It massively expands the potential use cases for businesses.
It's More Than Twice as Fast: Speed is not just a luxury; it’s critical for productivity. Fast models are essential for maintaining a "flow state", especially during creative or technical tasks like coding.

The Flow Zone Problem
If a developer is in a deep “flow zone” and has to wait 5 minutes for a large model to return a code suggestion, the spell is broken.
They check their phone.
They browse Twitter.
They lose concentration.
Productivity plummets.
A model that responds in seconds keeps the user in that high-productivity flow state. This makes faster, "good enough" models often better than slower, "perfect" models.

Creating quality AI content takes serious research time ☕️ Your coffee fund helps me read whitepapers, test new tools and interview experts so you get the real story. Skip the fluff - get insights that help you understand what's actually happening in AI. Support quality over quantity here!
The Shift from Behemoth to Specialized
The Old Paradigm: Massive, generic models like GPT-4.5 (rumored to be 17-20 trillion parameters). These models are slow, expensive and often require a $200/month subscription.
The New Paradigm: Specialized, small, super-fast models (in the 1-2 trillion parameter range). These are far more efficient.
The New Inference Compute Strategy
The old approach was to use all available compute to train the biggest possible model, which then ran slowly during inference (use). The new, smarter approach is:
Train a medium-sized model (like Sonnet 4.5).
Use the remaining compute budget during inference (test-time compute).
This "test-time compute" allows the smaller model to "think longer", reason and explore different paths before giving an answer.
The result is often a better, more thoughtful outcome from a smaller, faster model that has been given time to reason.

Part 7: The Multi-Hour Agent Breakthrough
Perhaps the most important chart in the AI revolution right now tracks the maximum time an agent can work meaningfully by itself.
Six months ago: ~20 minutes.
Today (Q4 2025): ~2 hours.
This is big growth and it’s unlocking new categories of tasks that were impossible just last year. We are seeing reports of GPT-5 Codex running for 7-hour autonomous work sessions and Claude Sonnet 4.5 for 30 hours (though the latter is likely an outlier). A realistic range is 2-7 hours of sustained, autonomous, meaningful work.

Why This Matters: Unlocking Complex Tasks
Before this breakthrough, agents could only handle simple, short tasks. Now they can:
Conduct deep, multi-stage research (a feature now ubiquitous in chatbots).
Perform massive codebase refactors that take 30-90 minutes.
Complete complex, multi-step workflows that require sustained context over hours.
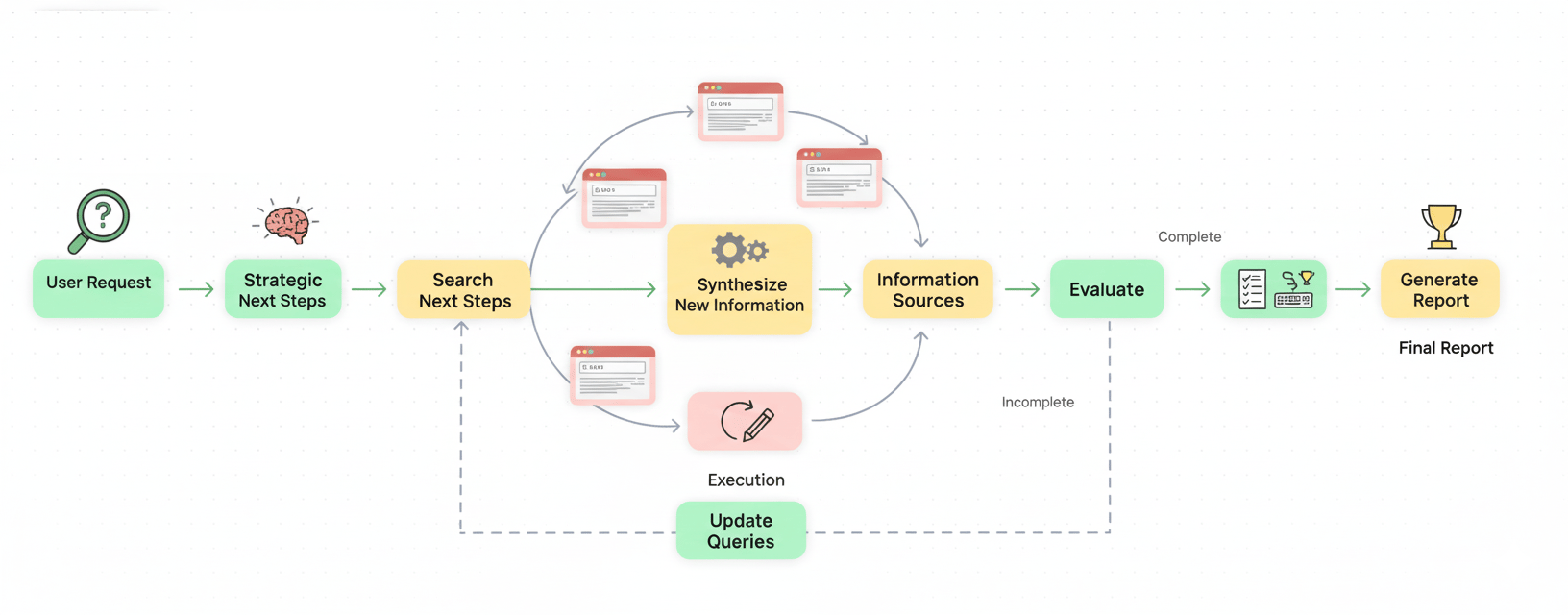
The "Deep Research" Workflow Explained
"Deep Research" is a perfect example of a multi-hour task. It's incredibly compute-intensive. A single deep-research query uses hundreds to thousands of times more compute than a normal query. The workflow involves:
Analyze the user's request.
Determine what data already exists and what is missing.
Plan strategic next steps (e.g., "I need to search for these 5 terms").
Execute those searches.
Synthesize the new information.
Repeat this loop until the goal is met.
Generate a final, clear report.
The Future: Multi-Day Agents
If this trajectory continues, we will soon have agents that can work reliably for multiple days. This unlocks the ability to automate tasks that currently require a junior engineer or intern multiple weeks to complete. The AI will still be faster, better at processing data, summarizing and outputting results.
Part 8: The Infinite Money Glitch
While the technology is fascinating, the financial side of the AI race reveals a strange, self-reinforcing loop, especially between NVIDIA and the major AI labs.
How NVIDIA and OpenAI Print Money
Here is the simplified “infinite money glitch”:
NVIDIA (the chipmaker) invests $100 billion into OpenAI (the model builder).
OpenAI receives the $100 billion in cash.
OpenAI must spend that money on "compute" (GPUs) to train its next-generation models.
That money goes right back to NVIDIA (or to cloud providers like CoreWeave, who in turn spend it all on NVIDIA GPUs).
Perhaps 80-90% of the initial investment returns to NVIDIA as revenue.
NVIDIA shows higher revenues, which increases its stock price and valuation.
This higher valuation enables NVIDIA to make even more investments, starting the loop over.

The Profitability Problem
This loop highlights a critical truth: almost everyone in AI is losing money. Finding a profitable AI startup is nearly impossible, let alone a profitable AI research lab. They are burning millions (for startups) or billions (for major labs) on training and compute costs.
Who's Making the Real Profits?
Jensen Huang and NVIDIA. They are the ones with amazing profit margins, selling the "picks and shovels" in this digital gold rush. This explains why everyone else - OpenAI (with Broadcom), Amazon, Google (with TPUs) and Meta - is desperately trying to design their own custom chips. They need to gain independence from NVIDIA.
Owning the full stack, from silicon to AI model, means you control your own destiny. You are not dependent on another company's GPU allocation. You can execute flawlessly or fail on your own merits. This is why NVIDIA, as a potential $10 trillion company in 2-3 years, is seen as an easy prediction by many analysts.

Jensen Huang and NVIDIA
Part 9: Compute is the Bottleneck
If you listen to anyone who actually matters in the AI race - research lab leaders, chip designers, GPU manufacturers, data center builders - they all talk about one thing: compute.
Compute is the true bottleneck, not (at the highest level) data or talent.
The Demand Problem
The reality is that companies like Anthropic and OpenAI have far more demand for their products than they can possibly serve.
Example: ChatGPT Voice. Why is it often only available on mobile? Why is it restricted to the highest-paid subscribers?
The Answer: The compute costs are too high. They are compute-constrained.
The Opportunity: All the big AI companies could easily 2-3x their revenue tomorrow if they just had more GPUs to serve the existing demand.

Career Advice: Follow the Money
Want to make a fortune in the AI revolution? Become an expert in:
Chip design
Silicon design
Data center infrastructure
This is the real, physical bottleneck of the AI boom.

Second and Third-Order Consequences
Because compute is the bottleneck, the "smartest money in the world" is flooding into solving it. This money isn't just going to speculative startups; it's going into real assets like multi-gigawatt data centers. OpenAI's latest project is rumored to be a 10-gigawatt data center - enough to power a small country.
Wall Street loves this. Data centers are a business model they understand. They are like real estate: predictable revenue, long-term tenants paying rent. It’s much easier to invest in this understandable infrastructure than in a “speculative AI startup with another vibe coding tool.”

Part 10: Everyone's Building the Same Thing
Despite massive investment, the startup landscape is suffering from a critical lack of imagination. Two categories are completely dominating the new startup scene.
Vibe Coding Tools (Clones of Bolt, Lovable, v0)
n8n Clones (AI-powered workflow builders)
The Problem: Winner-Takes-All
It's not just startups. Major players are joining in. OpenAI just released Agent Kit, their own workflow builder. But this doesn't mean n8n is dead. Both n8n and Agent Kit will likely succeed because they serve different markets: Agent Kit for beginners in the ChatGPT ecosystem and n8n for more technical users.
But the real problem is that everyone is building the same thing. ElevenLabs (a voice company) and Firecrawl (a web crawler) have both released agent builders. Why? This market is becoming saturated. If you're already a master of n8n, why would you switch? If you're used to Bolt, why switch to an identical competitor?
The Innovation Problem (The 0-to-1 Gap)
What's missing is true innovation. We are seeing a thousand "1-to-1.1" improvements, not "0-to-1" breakthroughs. Inspired by Peter Thiel's Zero to One, the goal should be to:
Create something that doesn't exist.
Target a small, specific market.
Build a monopoly by delivering a 10x better solution.

Today's vibe coding tools are not 10x better than each other. They are maybe 50% better, 2x at best. Therefore, most of them will fail.
The Token Reselling Problem
Many of these new startups are also built on a house of cards: they are very unprofitable because their entire business model is reselling OpenAI or Anthropic tokens at a loss to acquire users. This is not sustainable.
Prediction: Many of these copycat, unprofitable startups will fail within the next 24 months.
Part 11: The Coming Labor Disruption
This is the easiest and most serious prediction: the AI revolution is going to take jobs and it will lead to massive social unrest.
The Economic Reality
Look at the market sizes:
The entire software market is worth ~$300 billion/year.
The entire global labor market is worth ~$15 trillion/year.
Where is the real money? It's not about replacing software. It's in replacing human labor.

The 2026 Trend: Single Job Replacement Agents
This is already happening at stage one and it will accelerate.
Customer Support: The most obvious target.
Secretaries/Assistants: Advanced voice and scheduling tools.
Sales Setters & Outreach: Agents can handle initial prospecting and booking.
Most AI revenue growth will come from replacing repetitive, boring, low-level automation tasks. This is the modern equivalent of the automatic elevator replacing the elevator operator.

The Dual Outcome
This will create two distinct outcomes:
Positive Side: Massive efficiency gains, huge productivity improvements and incredible returns for investors and companies.
Negative Side: Significant, rapid job losses, leading to social unrest and widespread protests.
Safe Prediction for 2026: We will see widespread protests across the globe directly related to AI-driven unemployment.

Part 12: The Return of Learning to Code
Here is a surprising prediction: in the age of AI, learning to code will become "sexy" again. People will rush to learn computer science and software engineering.
Why? Because understanding coding creates a massive, unfair advantage with AI tools.
The Skill Multiplier Effect
A Non-Technical Person (e.g., someone who struggles with browser settings) can use AI to become 2-3x faster at their tasks. This is a good improvement.
A Skilled Programmer (who understands code, systems and logic) can use AI to manage teams of agents, build custom automations and solve complex problems. They become 100x more powerful.
The Smart Get Smarter
The new reality is that AI helps those who are already highly skilled much more. If you are "locked in" and at the cutting edge of AI, you will crush everyone else. The biggest takeaway is this: if you can do one thing for your career, get to the cutting edge of AI.

Conclusion: The AI Revolution is Real
After 28 months of direct AI work, the verdict is certain: AI is not a bubble. It is a fundamental transformation of how humans work and create, backed by clear evidence:
Real Revenue: 10x year-over-year growth, not just speculation.
Genuine Use Cases: Real, daily utility for hundreds of millions of people.
Continuous Breakthroughs: Progress is accelerating with reinforcement learning and multi-hour agents.
Massive Investment: The world's smartest money is pouring into the physical foundation of AI - compute and data centers.
What's Actually Happening
The key trends are clear: open-source models are catching up to closed-source, smaller and faster models are becoming more useful than giant ones and compute remains the single critical bottleneck. This transformation will also bring real challenges, including unavoidable and painful job displacement.

Where We're Headed
The era of copycat startups is ending. The future belongs to those who gain true technical skill - a "return to code" that provides a 100x advantage.
The opportunity is unlike anything before but it’s not for people just trying it out. It’s for those who commit to reaching the cutting edge of the most significant technological revolution in human history.
If you are interested in other topics and how AI is transforming different aspects of our lives or even in making money using AI with more detailed, step-by-step guidance, you can find our other articles here:
AI and Jobs: How Artificial Intelligence is Changing Work Worldwide
Google Is Killing Its $200B Golden Goose*
*indicates a premium content, if any
✨ How would you rate this AI Visionaries article?Help us improve by picking one that fits: |
Reply