- AI Fire
- Posts
- 💅 OpenAI's Translator is Slayyy
In partnership with

Plus: 10 Lazy Methods to Start ChatGPT Passive Income. Stop Being Normal GPT Users (Free Guide)
OpenAI launched ChatGPT Translate and it might be the first real threat to Google Translate in years. Meanwhile, DeepSeek just solved the biggest LLM bottleneck!
What's on FIRE 🔥
IN PARTNERSHIP WITH 1LEARN

Unlock Vibe Coding: Create App, Website and Product in 3 Hours Masterclass
Session on Saturday 17th January • 9:00 AM EST
Imagine creating browser extensions, mobile apps, plugins, and micro-SaaS — all without writing a single line of traditional code. That’s the power of Vibe Coding, a brand-new way of building with AI.
In this 3-hour Masterclass, you’ll learn how to turn your ideas into fully working apps using the most powerful AI tools - Lovable, Bolt, Cursor, Replit, Claude, Supabase and more.
🔥 What You’ll Experience:
💡 Turn raw ideas into real apps (live demo)
🛠️ Build using beginner-friendly AI platforms
📱 Create your first AI-built app during the session
⚡ Discover how Vibe Coding helps you build 10x faster
No coding. No technical background. No complexity.
🎯 Join the Masterclass and learn to build real AI products.
AI INSIGHTS

Click to try using it in real-world cases
Google Translate has had the language game locked for years. But OpenAI just launched ChatGPT Translate, a standalone web translator with one major twist:
You can now tell your AI translator to be more fluent, more academic, more business formal, or more casual, right from the interface. It’s tone-aware translation. It’s:
“Translate this and make it sound like a university professor.”
“Translate this casually like a text.”
“Make it sound more fluent.”
Google Translate doesn’t do that kind of tone flexibility. GPT Translate now supports 50+ languages, text input or voice input on mobile browsers.
They haven’t said which model powers it, but it’s likely GPT‑4 Turbo under the hood. Honestly, Google Translate is everywhere. But it’s also kind of frozen in time.
OpenAI is now going after intent. This is especially good for business users, students, creators, basically anyone who doesn’t want their translation to sound like a robot.
Google Translate might win on formats (images, documents, websites) but OpenAI is coming for the next layer of value, like context, tone, and quality.
🎁 Today's Trivia - Vote, Learn & Win!
Get a 3-month membership at AI Fire Academy (500+ AI Workflows, AI Tutorials, AI Case Studies) just by answering the poll.
What GPT Translate feature is mentioned but not available yet? |
PRESENTED BY WISPR FLOW
Better prompts. Better AI output.

AI gets smarter when your input is complete. Wispr Flow helps you think out loud and capture full context by voice, then turns that speech into a clean, structured prompt you can paste into ChatGPT, Claude, or any assistant. No more chopping up thoughts into typed paragraphs. Preserve constraints, examples, edge cases, and tone by speaking them once. The result is faster iteration, more precise outputs, and less time re-prompting. Try Wispr Flow for AI or see a 30-second demo.
AI SOURCES FROM AI FIRE
1. Use AI better than 99% of people & finish your weekly work in just 1 single day. Exact methods professionals use to get perfect results from any model instantly
2. 10 lazy methods to double your ChatGPT passive income. Stop being normal GPT users. We tested 10 simple ways to 2x your income without technical skills (Free)
3. Review Top 10 Free AI education tools to save you 10+ hours each week. These tools handle all lesson plans, grading, and slides so you can truly focus
4. The simplified AI model that prints $35K on autopilot. Real math, no marketing or hyped! Use this partner-led method to make companies send high-paying leads to your AI Business for a massive 80% profit
TODAY IN AI
AI HIGHLIGHTS
🧠 One Redditor shared their top 15 golden prompts after saving every great prompt over 6 months. These save 10-15 hours/week. Full list now trending in AI subreddit.
⚖️ New court docs dropped in the Altman vs. Musk fight. It’s messy. We know you don’t have time for all 3 pages, so Matt broke it all down here in this 10-min video.
👀 Google launched Personal Intelligence in Gemini. It links Gmail, Photos, YouTube,... to give personalized answers. Here’s how it can help & save you from a headache.
📈 OpenAI, Anthropic, and SpaceX might IPO in the same year. So 2026 could be the year of the “Mega IPO” with $2 trillion going public (according to a NYT report)
📚 Microsoft shut down its employee library, axed a bunch of news subscriptions, even ones used for 20+ years. They’re replacing it with “AI-powered Skilling Hub”.
📘 Wikipedia’s finally cashing in. They locked deals with Microsoft, Meta, and even Perplexity to pay for AI training access. Big Tech’s now paying for what they scraped.
💰 Big AI Fundraising: AI video startup Higgsfield reached a $1.3B valuation after its latest funding round, highlighting strong investor interest in AI video sectors.
NEW EMPOWERED AI TOOLS
📅 Cal.com Companion Apps is a native iOS & Android app/ browser extensions for scheduling
🤝 folk Assistants proactively researches companies, sends outreach emails, recaps ongoing deals, and sees who to follow up with
✈️ TeamOut AI gets tailored property recs, flight cost estimates, and exclusive hotel deals that save you 40%
👾 Kiki is the accountability monster that keeps you focused on a task
AI BREAKTHROUGH
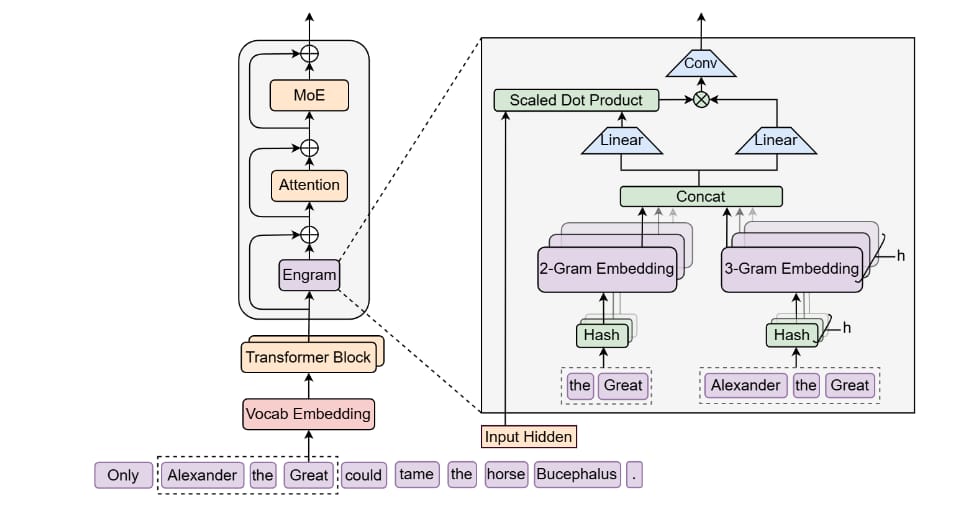
Figure 1. The Engram Architecture
Everyone’s racing to pack more context into models like 1M tokens, retrieval, bigger pipes. Meanwhile, DeepSeek just gave LLMs a real memory system, called Engram.
Most LLMs today waste compute "reconstructing" simple facts. Like a model doing calculus just to spell “Tokyo.” That’s because they don’t have built-in memory. Engram fixes that with conditional memory:
It uses N-gram embeddings, compressed representations of common phrases.
The model does a 1-step lookup instead of rebuilding answers
This instantly retrieves facts, freeing up depth for actual reasoning like math, code, logic
They found that performance actually dips at scale if memory isn’t handled correctly. But when they offload memory into Engram, performance rebounds.
This balance, between “thinking” and “remembering”, is called Sparsity Allocation, and it’s one of the biggest efficiency problems in LLMs today.
Will OpenAI, Anthropic, or Google follow this path, or double down on scale? Because if you can remember efficiently, maybe you don’t need to think so hard.
We read your emails, comments, and poll replies daily
How would you rate today’s newsletter?Your feedback helps us create the best newsletter possible |
Hit reply and say Hello – we'd love to hear from you!
Like what you're reading? Forward it to friends, and they can sign up here.
Cheers,
The AI Fire Team
Reply