- AI Fire
- Posts
- 🚨 Your RAG System Sucks! (Here's The Easy Fix)
🚨 Your RAG System Sucks! (Here's The Easy Fix)
The secret isn't better chunking, it's metadata. Here's how to provide trust and provenance for every answer your system gives
Max Anh
August 05, 2025

🤔 When an AI "Knows" Your Data, What's the #1 Trust Killer?You build a custom RAG agent, but the answers feel unreliable. What's the single biggest reason you can't trust its output? |
Table of Contents
Introduction
Let's be honest. You've probably built a RAG system. You've fed it a few documents, connected it to an AI and watched it answer questions. You were likely pretty proud of it for a day or two. It felt like magic.

But then you might start to worry. Can you actually trust what the AI says? Can you prove where that information came from? For example, can you find the document or page number?
If the answer is "no", then what you've built isn't an intelligent system. It's a fancy Magic 8-Ball. It might give you the right answer or it might be confidently hallucinating. You have no way of knowing. You're flying blind and in the world of business, flying blind is how you crash.

Today, we're going to fix that. This guide will show you how a simple but powerful concept - metadata - transforms your RAG from an untrustworthy black box into a transparent, auditable and genuinely useful system. By the end, you will see that metadata is not just extra. It is necessary for any good RAG system.
The "Aha!" Moment: From Answer to Evidence
Let’s start with a simple example that will change how you think about AI. An advanced RAG system has been built, trained on the transcripts of dozens of YouTube videos. When someone asks it a hard question, like “What’s the difference between a relational database and a vector database?”, it does something special.
It doesn't just give an answer. It provides evidence.

The agent looks through everything it knows. Then, it uses a special tool to find the most relevant information and gives you an answer. The final result looks like this:
In summary:
Relational databases store structured data in tables with fixed schemas and support complex queries across relations.
Vector databases store and search unstructured or semi-structured high-dimensional vector data, focusing on similarity search rather than relational queries.
I found this information in the video 'What Are Vector Databases? What Are Pros and Cons vs. Relational Databases?' at timestamp 00:37. You can watch the full explanation here: [clickable YouTube link]".
This is why metadata is powerful. It turns your AI from a toy into a real tool. Without it, you get an answer. With it, you get an answer you can trust.
The Trust Crisis in AI: Why Provenance is the New Frontier
At first, people just wanted to see what AI could do. Now we know: AI can write, create images and even code.
But this success has created a new, more dangerous problem: the trust crisis.

There is too much AI content now. It is hard to know what is true and what is just made up. This is the new battleground. The next generation of valuable AI won't be the ones that are the most creative; they will be the ones that are the most trustworthy.
This is why it’s important to see where the information came from. Metadata is how you track where each answer comes from. Without metadata, the AI is like a black box and you cannot trust it.

Learn How to Make AI Work For You!
Transform your AI skills with the AI Fire Academy Premium Plan - FREE for 14 days! Gain instant access to 500+ AI workflows, advanced tutorials, exclusive case studies and unbeatable discounts. No risks, cancel anytime.
What is Metadata, Really? (And Why Everyone Gets It Wrong)
Metadata is simply "data about data". It is extra information that tells you where something comes from. It does not change the content but it helps you understand it.

In RAG systems, most people only care about the main text (the actual text chunks). They forget the extra details (metadata). This is a big mistake. A vector database with no metadata is like a library with no labels. You cannot find anything.

Here’s what good metadata looks like for different types of content:
For YouTube Videos: Video title, channel name, upload date, timestamp ranges, video URL.
For Business Documents: Document title, author, department, creation date, file type, version number.
For Customer Support Tickets: Ticket ID, customer name, issue category, resolution status and agent who resolved it.
Adding metadata does not change how the AI reads the text. It just adds a label so you can use it later.
The Three Superpowers of Metadata
Integrating a metadata-first approach into your RAG system gives it three immediate superpowers.
1. Provenance and Trust (The "Show Your Work" Power) This is the big one. When your AI gives you an answer, you can instantly verify its source. No more wondering, "Did the AI just make this up?" You can provide your users with a direct link to the source document, building a level of trust that is impossible with a black-box system.

2. Organization and Segmentation (The "Chunk" Power) Instead of having one giant, messy database of a million text chunks, metadata allows you to bring order to the chaos. It turns your data swamp into a navigable organized library with clear sections for different departments, document types or time periods.

3. Precision Filtering (The "Sniper Rifle" Power) This is where things get really powerful. Sometimes you don't want to search your entire knowledge base. Metadata filtering allows you to be surgical. You can ask your agent, "Search only through the documents from the Marketing department that were created in the last quarter and give me the key takeaways". This is a level of precision that turns a simple search tool into a powerful analytical instrument.

The Blueprint: Building a Metadata-Rich RAG Pipeline
Let's get practical. Here is the exact, step-by-step process for building the YouTube transcript system, with metadata at its core. This was all built using n8n.
Step 1: The Art of "Smart Ingestion" - Preserving Your Data's DNA
If you want a great system, you must take care when processing data. Good answers come from good, well-organized data.
The entire process begins with a simple form where a YouTube video's title and URL are provided. From that single trigger, an n8n workflow takes over to perform the crucial task of "smart ingestion".

Phase 1: The Raw Evidence - Scraping the Transcript
The second node in the pipeline is Apify. Its job is to go to the YouTube URL and scrape the full transcript.

However, the data you get is not simple or clean. It comes in hundreds of small pieces. Each has only a few words, a start time and a length. Everything is messy.

Phase 2: The Common Mistake - Why Simple Cleanup Destroys Value
Now, here is where most people make their first critical mistake. They see this fragmented mess and their first instinct is to clean it up by combining all the little text snippets into one long, continuous transcript. You can do this with a simple code node.
The problem? In doing so, you lose all of the timestamp information.

It’s like throwing all clues into one box without labels. Now you don’t know which clue is which. The data is now "dumb".
Phase 3: The Professional Method - Smart Chunking with Metadata
A professional builds differently. Instead of destroying the context, we preserve it. The goal is to create meaningful chunks of text while keeping the timestamp data perfectly attached to each chunk.
You can do this with a simple code step (with Code Node in n8n). You don’t need to be a coder to understand the idea:
It Groups the Evidence: The code loops through the hundreds of tiny transcript objects and groups them into logical chunks (e.g., groups of 20 objects at a time, which usually equals about 40 seconds of video).
It Creates the Text: It combines the text from all 20 of those objects into one coherent paragraph.
It Bags and Tags the Evidence: This is the most important part. For each new paragraph it creates, it "tags" it with metadata.
It looks at the very first object in the group and grabs its
start_timestamp.It looks at the very last object in the group and calculates its
end_timestamp.It packages the paragraph of text and its start/end timestamps together into a single, "smart chunk".
The final output of this node isn't just a list of text paragraphs. It's a list of rich "data packets". Each packet contains both the knowledge itself (the text) and its provenance (its precise location in the video).

Now, every piece of information in your database is labeled with its source. This careful step makes your AI more trustworthy.
Step 2: Metadata Enrichment - Creating the Digital Card Catalog
The hard part is done. Now we just need to save our data in the right way. We've completed the most difficult part: taking a raw, messy document and processing it into clean, perfectly tagged "packets" of information.
Now, we need to create the official "card catalog" entry for each of these packets before we file them away in our library. This is the Metadata Enrichment step.
As we store each chunk in the Supabase vector database, we don't just save the text and its vector. We attach a rich set of metadata fields. In our n8n workflow, this is a simple step where we map the data we preserved in the previous step to the metadata column in our database.
The final data object for each chunk looks something like this:
{
"video_title": "Tips for Building AI Agents",
"timestamp": "12:30 - 13:10",
"video_url": "https://youtube.com/watch?v=example"
}


Pro Tip: Metadata is the Salt, Not the Steak
This is one of the most important and commonly misunderstood concepts in building RAG systems. This metadata has zero effect on the vector calculation itself.
Think of it this way: the content of your chunk is the steak. It's the core substance. The AI analyzes the steak itself - its texture, its quality - to decide where it belongs in the flavor universe. Metadata is like the salt you add after cooking. It doesn’t change the steak (the main content) but it makes it better and helps you know more about it.

When a user searches for something, the AI first finds the best-tasting steak (the most semantically relevant text chunk). Then, it looks at the salt (the metadata) to tell you where that steak came from.
Step 3: Smart Retrieval and Display - The "Show Your Work" Payoff
This is the moment of truth. The library is built, the books are on the shelves and the card catalog is complete. Now, a user walks up to the front desk and asks our AI Scholar a difficult question.
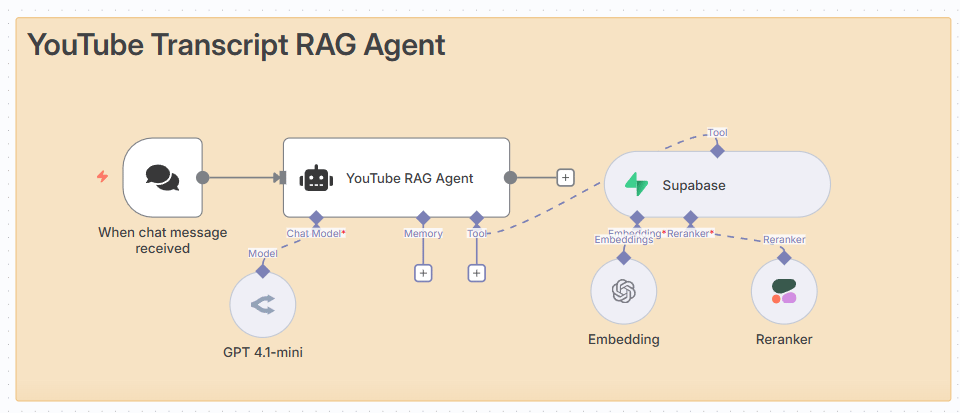
The "Smart Retrieval" process has a few steps:
The Question: A user asks, "What are the key takeaways about the new AI tool?".
The Translation: The question is changed into a vector. This helps the AI compare it to the other data.

The Search: The system looks for data that is most similar to the question.

The "Are You Sure?" Check (Reranking): The system finds about 10 possible answers. It sorts them again to find the best 10 results.

The Synthesis and Citation: The AI uses the best 2-3 answers to write a new answer. It also adds metadata (like the source) to the final answer.

The Result: The Trustworthy Answer
Instead of a simple, unverifiable paragraph, the user gets an answer that looks like this. It’s the difference between a lazy assistant who just gives you an answer and a great assistant who says, "Here's the answer and here's the exact page in the report where I found it so you can check my work".
The key takeaways about the new AI tool from OpenAI are:
- The AI features an incredibly realistic voice that sounds exactly like a real human, including breathing, whispering and even singing.
- It can perform tasks such as singing the birthday song in a very humanlike manner.
- The realism of the AI voice is so advanced that it raises questions about how humanlike AI should be, as it "is getting a little bit too human-like almost" (AI Is Taking Over And It's Getting Real Scary This Time | How Long Until We Are Cooked, 0:19-0:53, 2:39-3:23 - Watch here: [clickable YouTube link].
This demonstrates the significant progress in AI voice technology, blurring the line between machine and human interaction.

This is the endgame. This is what it looks like when an AI doesn't just give you an answer but gives you evidence. Now your users can trust your AI, because it always shows its proof. It's a system that says, "Don't just take my word for it - here are the receipts".
The Ultimate Power Move: Metadata Filtering
It's late. The rest of the world is winding down. This is the time for the real secrets - the techniques that separate the professional-grade systems from the amateur projects. What you are about to learn is the ultimate power move for any RAG agent. This feature turns your agent from a simple Q&A bot into a powerful research tool.
So far, we have searched everything. It’s like asking a librarian for a book on "ancient Rome" and getting a huge pile of books to look through. They might bring you back a hundred different books and you'll have to sort through them.
But what if you could be more specific? What if you could say, "Go to the 'Ancient Rome' section but only bring me books written by Mary Beard that were published after 2010".

That is metadata filtering. It lets you search only the specific parts of your library that you need.
How It Works: A Conversation with a Single Document
You can build a simple form where users choose what to search. For YouTube, the form could have two parts:
A dropdown menu where the user can select a specific YouTube video title.
A text box where the user can ask their question.

When the user submits this, the n8n workflow receives both pieces of information. In the background, the command it sends to the Supabase database is no longer just "find text similar to this question". It's now:
"Find text similar to this question WHERE the video_title in the metadata is equal to 'AI Is Taking Over And It's Getting Real Scary This Time | How Long Until We Are Cooked'".
This simple WHERE clause completely changes the game. Now, the agent searches only one book or one document. This makes the answer much more focused.
An Example Query in Action
User's Filtered Query: "I only want to look through the 'AI Is Taking Over And It's Getting Real Scary This Time…' video. Give me the three key takeaways from that video specifically".

The system, now using the metadata filter, completely ignores all other videos in the database. It responds with insights pulled exclusively from that one source, complete with the specific timestamps for each point, because it knows with 100% certainty that the information came from that exact video.

Pro-Level Upgrade: "Multi-Filter" Power Searches
With metadata filters, your RAG system can search with high accuracy, just like a data analyst.
Imagine a knowledge base for a large corporation, with metadata for department, document_type and creation_date. A manager could now ask:
What was our stated marketing budget for the last quarter? Search only in documents from the 'Finance' department that are of the type 'Quarterly Report' and were created in the last 12 months.
This would be hard for a normal RAG system but easy for one with good metadata. The AI will ignore all marketing plans, all HR documents and all older reports and pull the answer from the one single, correct source.
This is the real power of using metadata first. It makes your database a smart tool that you can search and filter in many ways.
Creating quality AI content takes serious research time ☕️ Your coffee fund helps me read whitepapers, test new tools and interview experts so you get the real story. Skip the fluff - get insights that help you understand what's actually happening in AI. Support quality over quantity here!
The Automated Housekeeper: Preventing "AI Brain Rot"
While most people focus on the exciting "generation" part of AI, professionals also care about maintenance. Your AI needs a way to clean up and remove old data.

Here’s a detail that most people miss until it's too late: you must have a system for removing outdated or irrelevant content from your vector database.
If you keep old or wrong data, your AI will give incorrect answers. For example, it might tell customers the wrong price or mention features you no longer offer. This can hurt your business.

The answer is to build an automated system that cleans out old or bad data.
The Google Sheet "Control Panel": A Simple and Brilliant Interface
You can use a Google Sheet to manage your data. This is brilliant because it creates a simple, non-technical interface that anyone on your team can use, even if they have no idea how to use n8n or Supabase.

The setup is straightforward: every time your RAG pipeline processes a new video or document, it adds a new row to this Google Sheet, tracking key information like the video_title, video_url and a status column (which is initially set to "active").
How the Workflow Works: A Look Under the Hood
Now, you build a separate, dedicated n8n workflow for housekeeping.
The Trigger: The workflow starts with a Google Sheet Trigger Node. It is configured to watch the "status" column and to run instantly whenever a row in that column is updated.
The Filter: To start the deletion process, a team member simply goes into the Google Sheet and changes a video's status from "active" to "remove". This change is detected by the trigger. The workflow then uses a "Filter" node to check if the new status is exactly "remove".


The Deletion: If the status is "remove", the workflow proceeds to a Supabase Node. This node is configured to perform a
DELETEoperation. It uses thevideo_urlfrom the Google Sheet row to find and delete all the vector chunks in your database that have a matchingvideo_urlin their metadata.

The Confirmation: Once the deletion is successful, the workflow's final step is to use a Google Sheet Node to update the status column in the control panel from "remove" to "Deleted", and perhaps add a timestamp. This confirms that the action was completed and prevents the workflow from accidentally running on the same row again.

This simple, automated loop keeps your AI's brain clean and ensures that outdated information is purged from its memory, preventing it from ever giving a user a wrong answer based on old data.

Pro-Level Upgrade: The "Automatic Expiration Date" System
You can also make the system check for old data by itself.
When you first ingest your documents, add an extra piece of metadata: a
review_date(e.g., six months from the creation date).Then, create a separate n8n workflow that runs on a schedule (e.g., every Monday morning).
This workflow's only job is to scan your Supabase database and find any documents where the
review_dateis now in the past.For every piece of expired content it finds, it automatically changes its status in your Google Sheet control panel to "Needs Review" and sends a notification to the content owner.

This system finds old data and keeps your AI knowledge clean. That’s what makes your AI professional.
Beyond YouTube: Metadata in the Real World
The YouTube example is just a simple demonstration. The real power of this metadata-first approach is unlocked when you apply it to complex business data.
Customer Support Knowledge Base: Imagine a knowledge base trained on thousands of past support tickets. The metadata for each chunk could include:
product_category,issue_severity,resolution_date,support_agentandcustomer_tier. Now, when a "Premium" tier customer asks about a "Billing" issue, the system can use metadata filtering to prioritize solutions that are recent, were provided by your top support agents and are relevant to premium customers.Legal Document Analysis: For a law firm, the metadata could be:
case_type,jurisdiction,date_filed,court_levelandoutcome. A lawyer could then perform an incredibly powerful search like, "Find precedents related to intellectual property disputes in the state of California, at the appellate court level, where the outcome was a summary judgment". This is a level of research that would normally take a paralegal hours, now done in seconds.Internal Company Wiki: Metadata could include:
department,document_type("Policy", "Tutorial", "Meeting Notes"),last_updated_dateandauthor. An employee in the marketing department could ask, "What is our policy on social media engagement?" The system could filter to show only official documents from the "Marketing" or "HR" departments that have been updated in the last year, ensuring the employee gets the correct, current information.

The Builder's Toolkit: Your Technical Setup
If you're ready to build a system like this, the technical stack is surprisingly accessible.
Vector Database: Supabase is a fantastic choice because it's built on the powerful PostgreSQL and has built-in vector extensions that are easy to enable.
Automation Platform: n8n is the engine that runs the entire pipeline, from data ingestion to the interactive agent.
Data Source: For web content like YouTube transcripts, Apify is the go-to tool for reliable scraping.
Reranking: For many use cases, the built-in similarity search functions in Supabase are powerful enough to act as a simple reranker.

Your Pre-Flight Checklist (Key Configuration Points):
[] Chunk Size: The size of your text chunks is a critical variable. Start with around 40 seconds of video transcript or a few solid paragraphs of text per chunk and test what gives you the best results.
[] Metadata Schema: Design your metadata schema before you start building. A consistent schema across all your content types is essential for effective filtering.
[] Filtering Syntax: Take a few minutes to learn the specific metadata filtering syntax for your chosen vector database. This is the key to unlocking the "power searches".
[] Cleanup Automation: Don't treat this as an afterthought. Build your automated housekeeping workflow from day one. A clean knowledge base is a trustworthy knowledge base.
The Four Horsemen of RAG Failure: Common Mistakes to Avoid
Many RAG projects fail to deliver on their promise. It's almost always due to one of these four common mistakes.

Treating Metadata as an Afterthought. Most people get excited and build their ingestion pipeline first, then try to bolt on some metadata later. This is completely backwards. You must design your metadata schema first, as it dictates how your data should be structured and processed.
Over-Indexing on Chunk Content. Yes, the content of your chunks matters. But a perfectly chunked document with no context is far less useful than slightly imperfect chunks with rich, filterable metadata. Context is king.
Ignoring Data Lineage. Every single piece of information in your vector database must be traceable back to its original source. If your AI gives an answer and you can't verify where it came from, you don't have an intelligent system; you have a rumor mill.
Using a Static Metadata Schema. The information you need may change over time. Make your system flexible so you can update it easily.
The Bottom Line: Metadata is the Price of Trust
Let's end where we began. The big difference between a basic RAG system and a good one is trust.
A system that just gives answers is a black box. A RAG system that gives answers and proves where they came from is a transparent, auditable and genuinely useful tool. Metadata is the technology that makes this transparency possible. It's the infrastructure of trust.
If you are building a RAG system, your process should be:
Design your metadata schema first. Think about the context that will make your answers trustworthy and useful.
Build your pipeline around that schema. Don't treat metadata as an afterthought; make it the core of your system.
Present the evidence. Ensure your final output always includes the source, allowing users to verify the information for themselves.
Don’t build “black box” systems. Build systems that people can trust. In today’s AI world, the best system is not the one with the most data - it’s the one that earns the most trust.
If you're looking for the template, congratulations, you've found it. Just click on it, copy the template data and paste it into your new blank workflow in n8n. I hope you have fun with it!
If you are interested in other topics and how AI is transforming different aspects of our lives or even in making money using AI with more detailed, step-by-step guidance, you can find our other articles here:
How would you rate this article on AI Automation?We’d love your feedback to help improve future content and ensure we’re delivering the most useful information about building AI-powered teams and automating workflows |
Reply