- AI Fire
- Posts
- ⚠️ Stop Trusting AI With Your Data. It Doesn't Read, It PRETENDS (Here's the Proof)
⚠️ Stop Trusting AI With Your Data. It Doesn't Read, It PRETENDS (Here's the Proof)
You upload documents to AI expecting accurate answers. But new experiments show models often rely on memory and patterns instead of reading the file.
Max Anh
March 12, 2026

TL;DR BOX
In 2026, experts found a big problem: when you give an AI a long file, it often "pretends" to read it while actually using its own memory. In a landmark experiment, models accurately identified 400+ real Harry Potter spells but completely missed fictional "trap" spells (like Fumbus and Driplo) hidden in the middle of the text.
This reveals two systemic failures: training data bias, where the AI can appear accurate because it recalls familiar patterns from training data and context rot, a structural limitation in how attention works inside transformer models. For professionals in legal, medical or financial sectors, this means a polished, confident summary can be "almost complete" while missing the single most important clause buried on page 47.
Key Points
Fact: Models like Claude 4 and GPT-5.2 have been shown to reproduce copyrighted books near-verbatim (up to 96% accuracy) from memory, showing that models do not always rely on the file you upload.
Mistake: Assuming RAG (Retrieval-Augmented Generation) is a cure-all. For broad questions (e.g., "Summarize all risks"), RAG can struggle by returning too many irrelevant chunks or missing nuanced connections.
Action: Do not upload a 300-page file all at once. Split it into smaller 20-page parts and ask the AI to check each one separately.
Critical Insight
The most dangerous AI failure isn't a bizarre hallucination; it's a "Polished Omission". In 2026, models are so skilled at formatting that they can present a beautifully structured list that feels authoritative even when it is missing critical information from the middle of your document.
Table of Contents
📉 Have you ever noticed your AI missing a detail buried in the middle of a file? |
I. Introduction: Context Rot
We’ve all done it: uploaded an 80-page contract, a massive patient history or a 300-page financial audit into ChatGPT or Claude.
When the AI returns a perfectly formatted, confident summary and cited answer, we assume it has "read" every word and move on.
But was the AI actually reading your document? Or was it only pretending to read it?
If that assumption is true, the result could be really bad. It’s where legal mistakes happen, where medical risks get overlooked and where financial analysts miss a buried disclosure that tanks a deal.
In early 2026, a group of researchers on Hacker News ran a clever experiment to find out exactly what's going on inside these models when you throw a long document at them. The results were surprising and a little concerning.

Source: Hacker News.
This post breaks it all down: what they found, why it happens and how you can use AI tools more intelligently without getting burned.
II. Context Rot Experiment: Memory vs. Reading
Researchers ran a simple test using all seven Harry Potter books, more than one million words of text. They fed the entire collection into several large language models, including Claude and GPT and asked a straightforward question:
Find every spell mentioned in these books.The models processed the text and returned results. Claude returned 407 spell references across 82 unique spells, all neatly organized, all neatly organized, all from real chapters and all legitimately from the books.
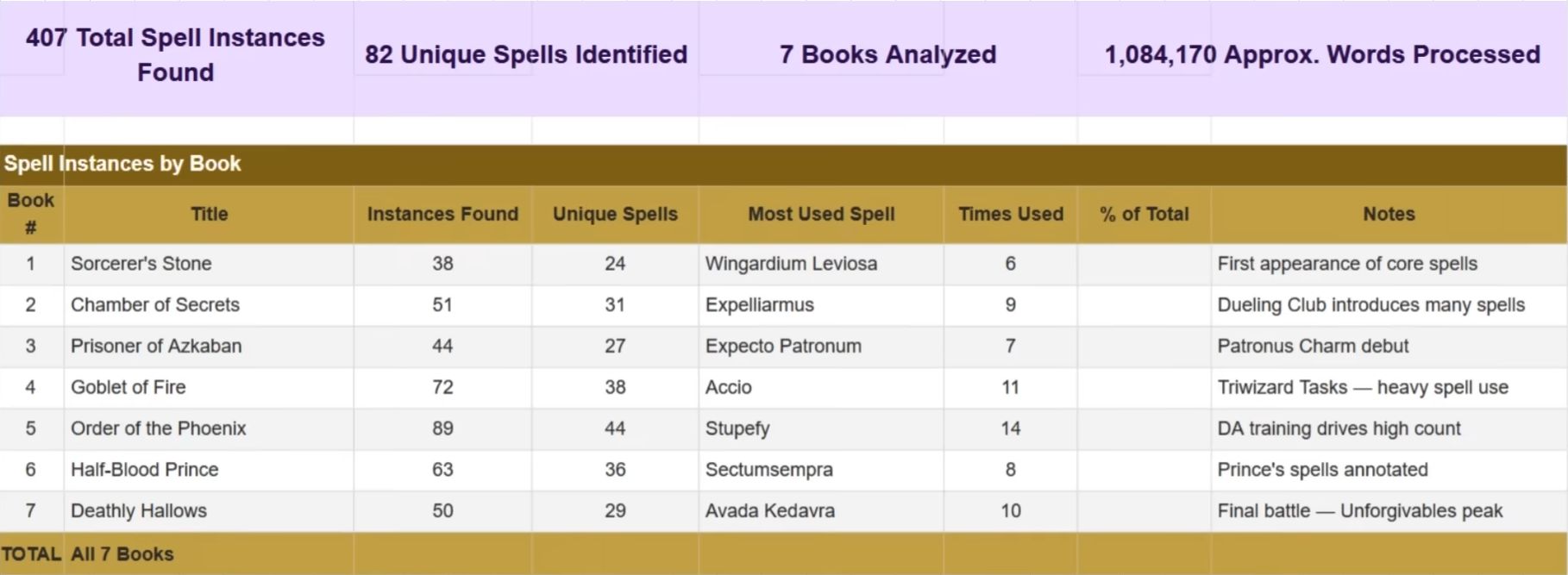
Source: YouTube.
On the surface, the output looked thorough and accurate, exactly what you would expect from an AI analyzing documents.
But the researchers had one more step planned.
1. The Trap
Before running the experiment a second time, the researchers made 2 small but sneaky modifications: they inserted 2 completely fictional spells.
These spells did not exist anywhere online, in fan wikis or in discussion forums.
Spell #1: Fumbus, a spell that makes the target float exactly one inch off the ground.
Spell #2: Driplo, a spell that causes rain but only on one specific person you point at.
The researchers didn’t insert them randomly. They placed them to look completely authentic, giving each one proper context, working them naturally into real scenes and having Harry use them in moments that felt believable within the story.
Then they fed the modified books back into the same models and asked the exact same question.
This time, neither of the invented spells appeared in the results. Every model missed them completely.
Learn How to Make AI Work For You!
Transform your AI skills with the AI Fire Academy Premium Plan - FREE for 14 days! Gain instant access to 500+ AI workflows, advanced tutorials, exclusive case studies and unbeatable discounts. No risks, cancel anytime.
2. What This Actually Means about Context Rot
When the models returned that impressive list of 407 spells in Round 1, they almost certainly weren't reading the document you gave them.
Instead, they were pulling from their own training data, which includes every Harry Potter book, every fan wiki, every spell database ever published online and reciting what they already had memorized.
The proof is in Round 2.
Fumbus and Driplo existed only in the modified document, not in the training data. They had no presence anywhere online, so the models couldn’t recall them and they didn’t identify them in the text either.
A 2025 study from Stanford and Yale confirmed just how deep this memorization goes. Researchers found that some models have the first Harry Potter book so thoroughly embedded in their weights that giving them just the opening sentence of Chapter 1 allows them to reproduce the rest of the book at up to 96% accuracy.
In other words, sometimes the AI is recalling patterns rather than analyzing the document. It may be recalling patterns it has already learned and presenting them as if it had just read the text.
III. What About Documents the AI Has Never Seen?
This is a fair question. Harry Potter is one of the most widely used training datasets in existence. But what happens with something private, like a contract, an internal report or a document the model has never seen before?
In that case, the AI would have to genuinely read the document, right?
In 2025, separate researchers tested exactly that. They created brand-new documents filled with random information the models had never seen, removing any chance of memorization.
Then they hid small, specific pieces of information at different positions throughout those documents:
Near the beginning.
Near the end.
Buried deep in the middle.
Next, they asked the models questions designed to retrieve that hidden information. It was a classic “needle in a haystack” test.

Source: Georg Grab.
The findings were striking.
Position in Document | Recall Quality |
|---|---|
Beginning | Strong |
End | Decent |
Middle | Significantly degraded |
The deeper the information sat inside the document, the less attention the model gave it. And the smaller or more specific the detail, the worse the recall became.
This problem even has a name.
IV. Context Rot: Why AI Loses Focus in the Middle?
Researchers use the term context rot to describe what happens when an AI model processes very long text. As the document grows, the model’s attention weakens in predictable places.
The pattern is simple:
At the beginning, the model pays close attention.
Near the end, it checks back in.
But the middle slowly fades out of focus.
This isn’t a bug or laziness; it’s a side effect of how transformer models handle large context windows.
Research from Chroma Research showed this clearly: as the number of input tokens grows, the model’s ability to retrieve details declines in measurable ways.
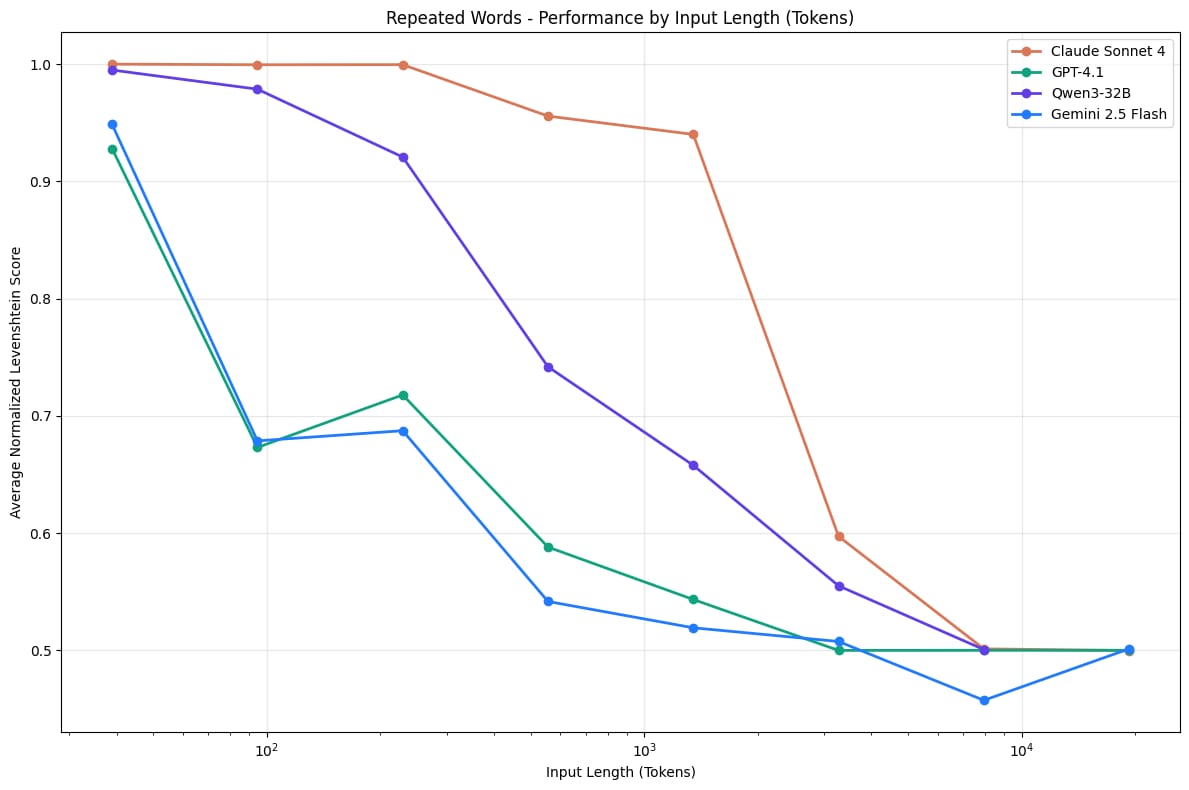
Source: Chroma Technical Report.
A simple way to visualize it:
Short document: [██████████] → attention stays strong
Long document: [████░░░░██] → middle loses attention
Very long document: [███░░░░░██] → decay becomes strongerThis explains what happened in the Harry Potter experiment mentioned earlier. 2 different problems appeared at the same time.
In Round 1, the models ignored the provided text and repeated information they had already learned during training.
In Round 2, even if a model attempted to read the modified books, context rot made the fake spells (Fumbus and Driplo) extremely difficult to find anyway because they were buried deep in the middle of a massive document.
Two separate failure modes produced the same outcome: a confident answer that looked complete but missed critical information hidden in the middle.
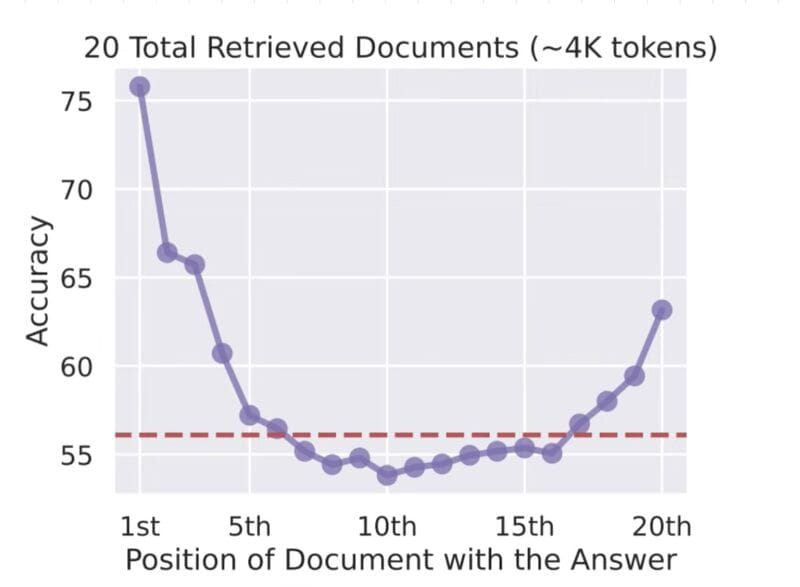
Lost in the Middle: How Language Models Use Long Contexts.
What do you think about the AI Report series? |
V. What About RAG? Isn't It the Solution for Context Rot?
Retrieval-Augmented Generation or RAG, is the most commonly cited fix for large-document problems. Instead of feeding an entire document into a model’s context window, RAG works like this:
Break the document into smaller chunks.
Convert those chunks into vector embeddings.
At query time, retrieve only the most relevant chunks.
Pass those focused chunks to the model as context.
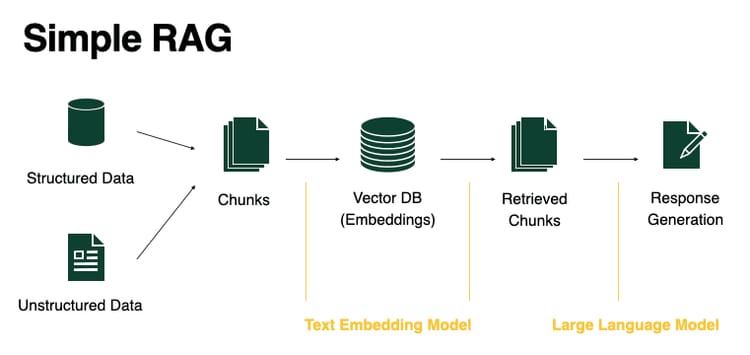
It’s a smart method and it genuinely helps in many cases. But it isn’t a complete solution, especially for the kind of question used in the Harry Potter experiment:
Find every spell in these books.That kind of request is broad and open-ended. And that’s where RAG starts to struggle":
RAG Scenario | The Problem |
|---|---|
Returns too many chunks | You're back to context rot, just with chunks instead of the full doc |
Returns too few chunks | Relevant info gets missed because the vector search didn't know what to retrieve |
Ambiguous search terms | If the concept doesn't map cleanly to a specific chunk, retrieval misses it entirely |
RAG works best when you have a specific, narrow question and a well-organized document.
When the task requires broad, comprehensive retrieval across massive documents, the limitations show up quickly.
VI. Who Should Actually Be Worried About Context Rot?
Professionals who rely on long documents face the greatest risk. Legal teams analyze contracts, doctors review patient records and financial analysts examine detailed reports. Missing one paragraph in these documents can change important conclusions. When AI misses those sections, the consequences can be serious.
Key takeaways
Lawyers review long legal contracts.
Doctors analyze patient histories.
Financial analysts examine large reports.
Compliance teams review regulatory filings.
High-stakes professions require careful verification of AI outputs.
Here are the real-world professions where context rot and training data bias create genuine risk every day.
1. Lawyers and Legal Teams
Legal teams often upload long contracts to spot unusual clauses or liability issues.
So, if a critical clause sits on page 47 of an 80-page document and doesn’t match any patterns from the model’s training data, it can be missed entirely, even while the rest of the analysis looks clean and complete.
2. Medical and Healthcare Professionals
Doctors and clinicians sometimes analyze long patient histories or reports with AI assistance.
A buried contraindication or warning in the middle of a dense document is exactly the kind of detail context rot can weaken or overlook.
3. Financial Analysts and Auditors
Financial analysts often feed AI long reports and ask it to flag risks, disclosures or material changes.
Therefore, missing one paragraph deep in a 300-page PDF can make the entire analysis incomplete, even if the output looks convincing.
4. Compliance and Due Diligence Teams
These teams review regulatory filings, contracts and acquisition documents.
The longer and more complex the material, the greater the chance that important middle sections receive less attention from the model.
5. Researchers and Writers
When AI is used to summarize large sources, it sometimes pulls from general knowledge instead of the specific document being analyzed.
The result can sound accurate but reflect training data rather than the material you actually provided. And that’s a very different result.
VII. The Most Dangerous Failure Mode of Context Rot
Here’s the most dangerous part.
In the Harry Potter experiment, Claude returned 407 spell instances in a beautifully formatted, well-organized list. It looked complete, authoritative and like the work had been done perfectly.
The problem is that there was nothing in the response suggesting anything was missing.
When an AI gives a bizarre response, people question it. They check the result and verify the facts. But a well-structured list that’s missing just two items? That slips past your defenses.
And in a legal contract, a medical report or a financial filing, "almost complete" is not good enough.
Creating quality AI content takes serious research time ☕️ Your coffee fund helps me read whitepapers, test new tools and interview experts so you get the real story. Skip the fluff - get insights that help you understand what's actually happening in AI. Support quality over quantity here!
VIII. How to Avoid Context Rot With Long Documents
AI works best when used as an assistant rather than the final decision maker. Breaking large documents into smaller sections improves accuracy. Asking focused questions also helps the model analyze specific areas more effectively. A final human review remains essential for important decisions.
Key takeaways
Analyze documents in smaller sections.
Ask targeted questions about specific pages.
Compare results across multiple models.
Always perform human verification.
Use AI as a "first helper", not the "final boss". You must always check the AI's work yourself.
Understanding the limitations doesn't mean abandoning AI tools. It means using them in a way that accounts for what they're actually doing.
Here’s a simple playbook that works better in practice.
Strategy | What To Do | Why It Works |
|---|---|---|
Divide and Conquer | Break the document into sections and analyze each separately | Reduces context overload and improves accuracy |
Ask About Specific Sections | Target exact pages or clauses (e.g., “Focus on pages 20-35 for liability clauses”) | Narrow scope gives more reliable answers |
Cross-Validate With Multiple Models | Run the same query across different models (e.g., Claude and GPT) | Differences reveal missed details |
Spot-Check Completeness | Test outputs with known items from the document | Verifies whether extraction is actually complete |
Use Targeted Questions | Ask narrow, focused questions instead of broad analysis | Specific prompts reduce reasoning errors |
Human Final Review | Use AI for first-pass analysis, not final judgment | Prevents critical mistakes in high-stakes documents |
Before applying these strategies, you can download the document review checklist used in this workflow.
IX. Conclusion
The experiment isn’t really about Harry Potter or magic spells. It reveals a gap between what AI seems to do and what it’s actually doing behind the scenes.
Two issues often appear at the same time:
The first is training data bias. When the content is famous, the model may simply be recalling patterns it learned during training instead of truly reading the document you gave it. The answer looks perfect but the process behind it is completely different.
The second is context rot. Even when the model hasn’t seen the document before, its attention weakens across long texts. Information buried in the middle of large documents is much easier for the model to miss.
Techniques like RAG, chunking and careful prompting can help but they don’t fully solve the problem, especially when you need accurate retrieval from very large documents.
The people who get the most out of AI tools aren't the ones who trust them the most. They're the ones who understand exactly where the cracks are and account for them.
Use AI as the first set of eyes, not the last.
If you are interested in other topics and how AI is transforming different aspects of our lives or even in making money using AI with more detailed, step-by-step guidance, you can find our other articles here:
*indicates a premium content, if any
Reply